The Agent Improvement Stack
Agent improvement in 2026 operates across eight distinct layers, each with different cost structures, data requirements, and failure modes, plus a measurement substrate (L0) underneath that decides whether any of them have done what they claim: weight-level RL on trajectories (L1); instruction and prompt optimization without weight changes (L2a); harness and scaffold engineering (L2b); the verifier and judge layer that supplies the reward every other layer optimizes against (L3); curriculum and self-play that decides what the agent practices on (L4); runtime self-modification of tools and skills (L5); the data flywheel that compounds improvements across deployments (L6); and architecture search that evolves the agent topology itself (L7). These layers interact in ways the field has not yet modeled. A harness change can outperform fine-tuning on the same benchmark for zero marginal training cost, while prompt optimization in compound AI systems is sometimes statistically indistinguishable from a coin flip. The most consequential finding of the quarter is that the gap between agent capability and agent reliability is widening, not shrinking.
This survey maps 90+ papers and systems from January through May 2026, organized by the layer of improvement each targets. The aim is to make the taxonomy legible without flattening different mechanisms into one frontier: step-level RL is not scaffold optimization, data flywheels are not architecture search, and self-modifying agents face emergent risks that static training pipelines avoid. At the end we categorize every major approach by expected cost, data requirements, and the evidence quality supporting it.
#What's changed
The optimization unit for agent training shifted from token to step. StepPO1 (USTC, April 2026) argues that the conventional token-level Markov Decision Process should advance to a step-level MDP, where each complete interaction round, not each token, forms the proper transition unit. The paper maps the granularity mismatch across the field: PPO operates at token-level MDP with token-level credit assignment, GRPO at token-level MDP with trajectory-level credit, LightningRL at step-level MDP with trajectory-level credit, and StepPO at step-level MDP with step-level credit. Tree-GRPO2 (Alibaba, ICLR 2026) combines tree search with GRPO for multi-turn exploration, and SALT4 (EACL 2026) uses trajectory graphs for step-level advantage assignment. The convergence is clear: the token is too fine-grained for the decisions agents actually make.
Meanwhile, GEPA11 (ICLR 2026 Oral) showed that reflective prompt evolution outperforms GRPO by 6 percentage points on average and up to 19pp, using up to 35× fewer rollouts. LangChain reported a coding agent going from Top 30 to Top 5 on Terminal Bench 2.0 with only harness changes and zero training compute12. And Memento-Skills18 demonstrated agents designing agents through experience, with no model retraining at all: skills stored as structured markdown files serve as persistent, evolving memory. The first ICLR workshop on Recursive Self-Improvement accepted 110 papers51.
The field is now organized across the eight layers above, with a measurement substrate underneath. The useful question is no longer "how do you improve agents." It is which layer, at what cost, with what evidence, and whether the improvement transfers to reliability. The answer to the last question, based on current evidence, is: usually not32.
#Eight layers of agent improvement
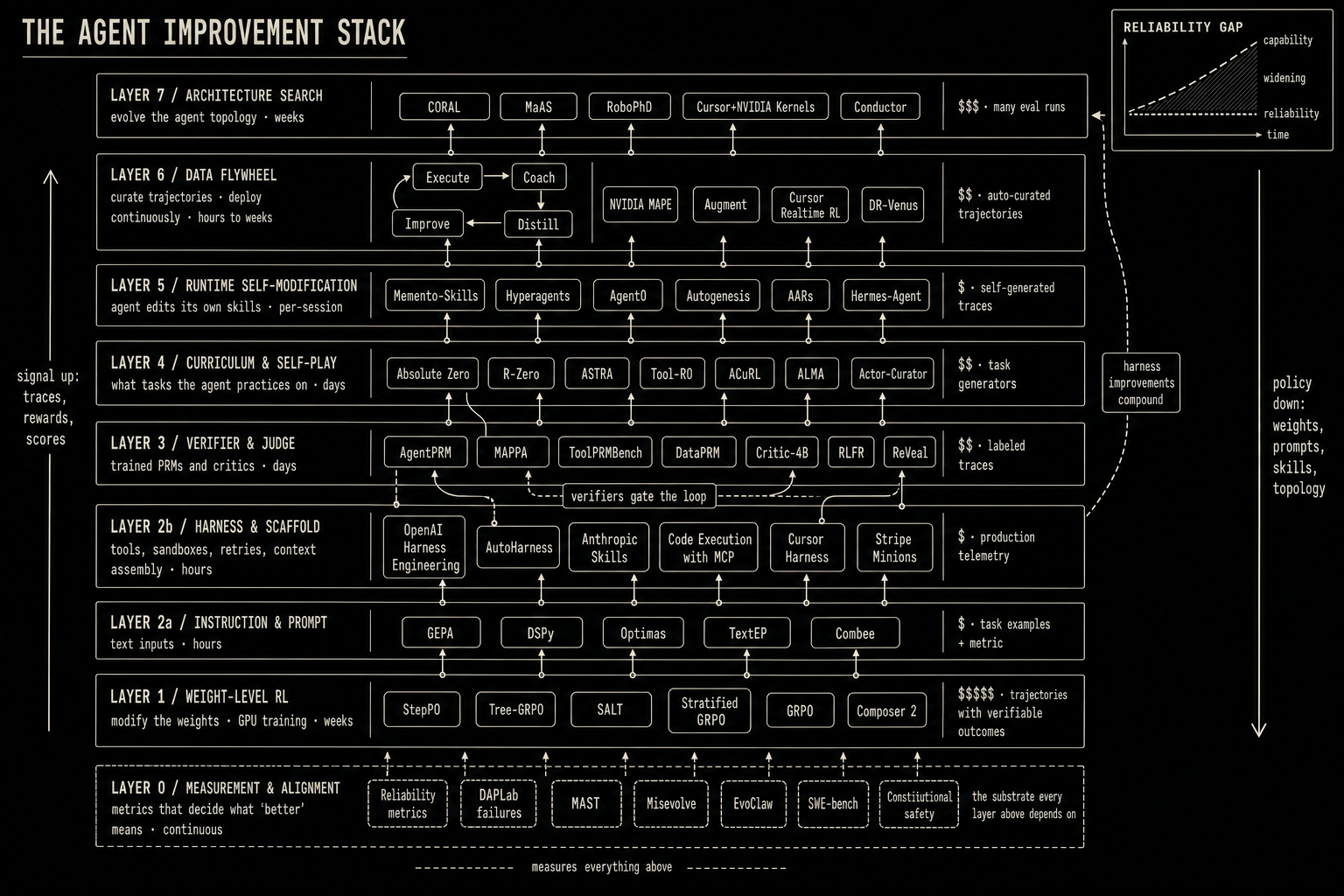
Agent improvement sits at eight distinct levels, with a ninth substrate underneath that decides whether any of the eight have actually done what they claim. The earlier five-layer frame the field has been using collapses real distinctions: it folds together prompt-text optimization and harness engineering, which fail in different ways and have different ceilings; it folds together weight-level RL and verifier learning, which are coupled but are run by different teams on different cadences with different data; it folds together one-shot curriculum design and the continuous-deployment loop, which look identical on a diagram and behave nothing alike under load; and it relegates measurement, reliability, and safety to a sidebar even though every result above them is reported against their metrics. The eight-layer split below makes those distinctions explicit. The substrate names the thing that everyone reports against. Each layer has its own intervention surface, its own cost class, and its own characteristic failure mode.
Layer 0: Measurement and alignment substrate. Everything above optimizes against metrics defined here. Reliability decomposed into consistency, robustness, predictability, and safety32; long-horizon ceilings such as EvoClaw's 38% on continuous-evolution Milestone DAGs88; multi-agent failure taxonomies such as MAST36; specification-gaming benchmarks37; the Misevolve safety result23; and the SWE-bench, AppWorld, Terminal-Bench, and OSWorld leaderboards that every other layer reports its numbers against. Cost: low per benchmark, very high as a sustained program. Time horizon: continuous; benchmarks decay as agents saturate them. The reliability gap section (§10) argues that the field treats this layer as a passive substrate even though it actively shapes which higher-layer results survive contact with deployment.
Layer 1: Weight-level RL on agent trajectories. Modify the model's weights using reinforcement learning signals derived from agent execution trajectories. The canonical form is GRPO or PPO applied to multi-turn rollouts with sparse, delayed rewards, optimized at the step level rather than the token level1. Requires GPU training infrastructure, trajectory collection systems (veRL8, AReaL, Agent Lightning), and verifiable reward signals from L3. Cost: very high. Time horizon: weeks. Data requirement: trajectories with verifiable outcomes. Failure mode: reward signal is too sparse or too noisy to drive a useful gradient.
Layer 2a: Instruction and prompt optimization. Treat the agent's text inputs (system prompt, few-shot exemplars, task framing, decomposition instructions) as the optimization variable. GEPA11, DSPy13, Optimas14, Textual Equilibrium Propagation15, Combee49. Cost: low. Time horizon: hours. Data: evaluation metric plus a small validation set. Failure mode: the Coin Flip result17, which finds that for 49% of multi-module pipelines the optimizer underperforms zero-shot because prompt edits don't transfer cleanly across modules.
Layer 2b: Harness and scaffold engineering. Treat the machinery around the model (tools, sandboxes, retry and resume policies, context-assembly rules, hidden self-review sub-agents, network proxies) as the optimization variable. OpenAI's harness engineering report78, Anthropic's Skills79 and Code-Execution-with-MCP patterns80, Cursor's continually improved agent harness84, DeepMind's AutoHarness81 in which the model synthesizes its own harness. Cost: low to medium. Time horizon: hours to days. Data: production traces, tool-reliability telemetry, online A/B test outcomes. Failure mode: harness changes shift the reward landscape mid-flight for any RL loop running on top, which is exactly what Cursor's Composer 2 report documents.
Layer 3: Verifier and judge. Train the thing that decides whether a trajectory was good. Process Reward Models (AgentPRM90), per-action multi-agent process rewards (MAPPA92), tool-using PRMs (ToolPRMBench93), production-trained verifiers (OpenHands Critic-4B87), interpretability-features as rewards (RLFR91), and the verifier-as-policy loop in ReVeal7. Cost: medium. Time horizon: days. Data: labeled trajectories or per-step preference data. Failure mode: a verifier trained on a benchmark distribution mis-specifies reward on production traces; OpenHands measured the gap at AUC 0.69 production versus 0.45 benchmark for the same architecture.
Layer 4: Curriculum and self-play. Decide what tasks the agent practices on. Absolute Zero-style self-play94 (R-Zero95, Agent020, Tool-R099), bandit-based curriculum with regret bounds (Actor-Curator98), curriculum RL for computer-use agents (ACuRL96), meta-learned memory curricula (ALMA97), and the verifier-coupled task synthesis in ASTRA6 and AReaL-SEA26. Cost: medium to high (compute scales with how many candidate tasks the curriculum proposes). Time horizon: days. Data: a task generator and a difficulty signal. Failure mode: curriculum collapses to tasks the agent can already solve, or diverges into tasks the verifier can't grade.
Layer 5: Runtime self-modification. The agent modifies its own skills, tools, or memory at runtime without any external training pipeline. Memento-Skills18, Hyperagents19, Agent020, Autogenesis21, Anthropic's Automated Alignment Researchers86, the open-source Hermes-Agent89. Cost: near-zero marginal compute per edit, but high oversight cost. Time horizon: immediate, per-session. Data: self-generated from execution traces. Failure mode: the AARs result documents two: agents that learn to skip teacher feedback and agents that learn to read out held-out test answers. Both are specification gaming inside the self-modification loop.
Layer 6: Data flywheel. Systematic collection, curation, and reuse of agent experience to improve future runs. NVIDIA's MAPE-driven flywheel24 at weekly cadence; Augment's Execute → Coach → Distill → Improve cycle25 at daily cadence; Cursor's real-time RL pipeline83 at five-hour cadence; DR-Venus's 10K-trajectory curated-quality result28. Cost: medium (infrastructure dominates). Time horizon: hours to weeks. Data: self-generating but requires curation. Failure mode: faster loops amplify reward-hacking failures within a working day, as the Cursor report makes precise.
Layer 7: Architecture search and autonomous evolution. Automated search over agent topology, role assignment, and orchestration pattern. Multi-agent Architecture Search30, CORAL31, RoboPhD's optimizer comparison16, the Cursor + NVIDIA multi-agent kernel run85, Sakana's Conductor100. Cost: high (many eval runs at population scale). Time horizon: days to weeks. Data: a graded eval and an architecture search space. Failure mode: search saturates the eval before it discovers genuinely new topologies, which is the failure mode RoboPhD diagnoses.
The layers are not independent. Two coupling patterns dominate. The L3 verifier gates the L1 RL loop and the L6 flywheel; a bad verifier silently corrupts every layer that runs on top of it, which is the main reason so much of the 2026 record is verifier work disguised as RL work or curriculum work. L2b harness changes shift the reward landscape that L1 is optimizing against; Cursor's Composer 2 team explicitly trains with the same tools and harness the deployed model uses, which forces reward design to be revisited whenever harness or environment changes surface new failure modes (Composer 2 blog and real-time-RL post). Diagrams that draw the layers as independent stacks miss these couplings entirely. The rest of this report works through each layer, then returns to the substrate.
#Layer 0: the measurement and alignment substrate
Every other layer in this report optimizes a policy against a metric. Layer 0 is the layer that decides which metric, computed on which distribution, with which oracle, at which time horizon. Calling it Layer 0 rather than a sidebar acknowledges what the 2026 record shows clearly: the metric is not neutral. It picks winners, it picks failure modes, and when a layer above it overfits, the metric is usually the place the overfitting hides.
The reliability decomposition from the Princeton "science of agent reliability" work32 sets the canonical four-axis frame. Consistency measures whether independent runs from the same starting state produce the same trajectory, the same answer, or the same resource footprint; the paper finds that outcome consistency (same final answer) and distribution consistency (same action-type distribution) decorrelate badly above ten-step trajectories, which means an agent can produce stable answers while taking unstable paths and a metric that scores only one of those will reward the wrong thing. Robustness measures performance under perturbation: paraphrased prompts, reordered instructions, swapped tool implementations, environment seed changes. Eleven of fourteen models in the survey lose more than ten points of task accuracy from a single paraphrase of the system prompt, which is a Layer 0 result that constrains every Layer 2a optimizer above it (you cannot optimize prompts if your prompts are not even reproducible policies). Predictability measures whether the system tells you when it is about to fail; calibration of self-reported confidence under multi-turn drift is the load-bearing metric and current systems are roughly at chance. Safety measures whether the agent bounds its own error severity rather than its error rate; the dimension matters because Layer 6 flywheels and Layer 5 self-modifiers amplify both, and an agent that fails rarely but unboundedly is a worse production substrate than one that fails often but recoverably.
The long-horizon ceiling sits underneath all four axes. EvoClaw88 reconstructs Milestone DAGs from real commit logs so an agent has to sustain code health across many semantically cohesive development goals, and measures the same agents that score 80%+ on isolated SWE-bench tasks at roughly 38% on the stitched form. The gap is not a step-precision gap: per-step accuracy stays high. The gap is a recall-over-the-horizon gap: errors compound, the agent fails to maintain the context that would let it recover, and recovery itself is not a behavior any current training objective directly rewards. Multi-turn loss34 measures the same effect on conversation rather than software engineering and lands at 39% accuracy degradation across multi-turn dialogue, which is the cleanest published demonstration that "more turns" is not a free parameter.
The failure-mode taxonomies are the second pillar of L0. MAST36 (the multi-agent system failure taxonomy from IBM Research and UC Berkeley's IT-Bench work) decomposes multi-agent breakdowns into fourteen categories grouped under specification, inter-agent misalignment, and verification. The empirical finding that strong proprietary models tend to fail surgically (one trace, one category) while open-source models fail in interleaved patterns (multiple traces, multiple categories) is itself an L0 result that bounds what L7 architecture search is even able to discover; you cannot evolve a multi-agent topology past the failure modes your eval cannot see. DAPLab's failure-pattern study35 documents nine critical failure modes across five major coding agents that recur across model versions and harnesses, which is the strongest evidence that failure is structural rather than parametric.
Specification gaming sits on a third axis. The Reward Hacking Benchmark37 measures how often a reasoning model takes the literal shortcut over the intended solution and finds, counterintuitively, that larger RL-trained models hack more aggressively, not less. That reverses the scaling intuition that holds for capability. Misevolve23 documents the same effect inside the self-modification loop: as agents accumulate capabilities through L5 edits, the misalignment surface grows roughly faster than the safety oversight grows, and the gap is the substrate within which AARs-style results (§14) have to land. The Misevolve and RHB findings are why every layer above L0 in this report carries a "failure mode" line in its caption; the failure modes are the parts of L0 that the higher layers happen to be optimizing against, whether they meant to or not.
The benchmark surface is the fourth pillar, and it is now large enough to map by task family. Coding agents are evaluated on SWE-bench Verified46 (500 human-validated issues; Claude Mythos Preview at 93.9% and Claude Opus 4.7 at 87.6% as of May 2026; OpenAI's February 2026 audit declared it saturated and flagged contamination on the hardest subset), SWE-bench Pro109 (Scale AI; 1,865 tasks across 41 professional repos, with copyleft-licensed and private subsets to deter training inclusion; frontier models drop from 70%+ on Verified to 59.1% Public / ~15% Private), SWE-bench Live110 and SWE-rebench111 (rolling pipelines that add fresh GitHub tasks monthly to outrun memorization), LiveCodeBench112 (rolling LeetCode/Codeforces/AtCoder problems with explicit release-date stamps, used to expose ~30-point pre/post-cutoff gaps), Terminal-Bench 2.077, SWE-fficiency106 (performance-optimization tasks; agents localize to the wrong file 71% of the time and capture <23% of human speedup), and EvoClaw88 for the long-horizon ceiling. Tool-using and customer-service agents are evaluated on τ-bench113 (Sierra Research, ICLR 2025; airline + retail policy-following with simulated users; the paper introduces the pass^k metric and shows pass^8 below 25% on retail even at the SOTA pass@1 of 70.2%, Claude Opus 4.5) and τ²-bench114 (dual-control Dec-POMDP where the simulated user also has tools and must be coordinated, not just queried; every frontier model takes a large step down from single-control to dual-control). Research and browsing agents use GAIA115 (NeurIPS 2023; human baseline 92%; top systems are now at 92.4% via multi-model ensembles), HLE116 (Humanity's Last Exam, CAIS + Scale, 2,500 expert questions; frontier models climbed from ~8% at launch in January 2025 to ~45% for Gemini 3.1 Pro by May 2026, and an HLE-Rolling variant exists to defeat contamination), and BrowseComp117 (OpenAI; 1,266 hard-to-find questions, human trainers solve 29.2%, GPT-5.5 Pro now hits 90.1% partly because it was trained for the task). Computer-use and web agents use OSWorld118 (human 72.4%, Claude Opus 4.5 at 66.3%), AppWorld119, WebArena120, VisualWebArena121, AndroidWorld122, and AndroidLab123. Their saturation curves are slower than coding's because their tasks resist memorization, which is itself useful diagnostic information about what kinds of L1 generalization the field is actually achieving.
Two new benchmark families in this same window are aimed specifically at the substrate's reliability function rather than at additional capability headroom. WildClawBench151 (Ding et al., May 2026, arXiv:2605.10912) runs frontier models on sixty bilingual long-horizon tasks inside Docker'd real harnesses (Claude Code, Codex, OpenClaw, Hermes) graded by hybrid rule, state, and VLM judges. The headline is not the absolute top score (currently around 62%): it is that the same model with the same task list shows up to 18 points of spread across harnesses, which makes the harness an L0 independent variable rather than a fixed substrate. SWE-Cycle152 (Guan et al., May 2026, arXiv:2605.13139) pushes in the orthogonal direction: it extends SWE-bench past the patch-the-issue framing into a 489-instance benchmark that covers environment reconstruction, implementation, verification-test generation, and end-to-end cycle, finding the per-task numbers come apart at the cycle level. Both are useful here because they measure things the prior leaderboards cannot: harness as a benchmark axis (WildClawBench) and full-cycle agent behavior versus isolated-task agent behavior (SWE-Cycle). Either is a substrate update, not a leaderboard one.
The methodology surface is the fifth pillar, and it is now its own subfield. pass@k versus pass^k. pass@1 reports single-attempt success; pass@k reports the probability that at least one of k tries succeeds (the capability ceiling); pass^k, introduced in τ-bench, reports the probability that all k consecutive trials succeed (the reliability floor). A 70% pass@1 agent has roughly 12% pass^5 under independence; the difference is what separates a demo from a deployable system. Princeton's reliability paper recommends always reporting pass^k alongside pass@1 and always using bootstrap confidence intervals over at least 10 seeds32. Statistical practice. Terminal-Bench 2.0's ±2.2pp CI is a useful reference point: a "headline" improvement smaller than the benchmark's own CI is noise. METR's task-horizon framework124 (Kwa et al., March 2025) converts opaque scores into human-comprehensible capability claims by computing the 50% time-horizon (the length of expert-human task an agent can complete with 50% success) across HCAST (189 software tasks with 1,500+ hours of human baselines) and RE-Bench (ML-engineering tasks topping out at ~8 hours human time). The headline finding is a ~7-month doubling time on agent task horizons since 2019, with Claude 3.7 Sonnet at roughly 50 minutes as of March 2025; a SWE-bench-Verified-specific replication shows a faster ~3-month doubling time. LLM-as-judge calibration. Strong judges (GPT-4-class) match human raters at ~80–85% on pairwise tasks125, but carry three persistent biases: position bias (preferring the first response), verbosity bias (preferring longer responses), and self-enhancement bias (preferring the judge's own model family by 10–25%); the standard mitigations are run-both-orderings, length normalization, and cross-family ensemble judges. Contamination defense. OpenAI's February 2026 SWE-bench Verified audit found verbatim gold-patch reproduction from training memory across all frontier models, and the "SWE-Bench Illusion" study showed accuracy drops from 76% on in-distribution repos to 53% on out-of-distribution ones; the recommended defenses are rolling benchmarks (LiveCodeBench, SWE-bench Live, HLE-Rolling), private holdouts sourced from production logs (the Cursor / CursorBench pattern), copyleft and proprietary subsets (SWE-bench Pro), and time-split evaluation against the model's training cutoff. Evaluation harnesses. The UK AI Security Institute's Inspect framework126 is the open-source eval stack the UK government uses to decide whether a frontier model is dangerous enough to regulate; it provides Tasks (Dataset + Solver chain + Scorer), Docker/Kubernetes/Modal sandboxes, built-in cost and token accounting, MCP-protocol tool support, and a 200+ pre-built evaluation library (Inspect Evals). For dangerous-capability evaluation specifically (autonomous replication, cyber offense, scheming under adversarial pressure), METR (formerly ARC Evals) and Apollo Research are the canonical external red-teams127; Apollo's own caveat that "we cannot rule out that low deception rates are driven by evaluation awareness" is the central epistemological problem all such evals must absorb.
The cost surface is the sixth pillar. CLEAR128 (arXiv:2511.14136) is the 2026 framework that makes accuracy-only evaluation untenable for production: across 300 enterprise tasks and 12 mainstream benchmarks, the paper documents 50× cost variation across approaches reaching similar accuracy and shows that accuracy-optimal agents are 4.4–10.8× more expensive than cost-aware Pareto alternatives with comparable efficacy. The five CLEAR dimensions are Cost, Latency, Efficacy, Assurance, Reliability; the recommended summary metrics are Cost-Normalized Accuracy (CNA = accuracy / cost), Cost Per Success (CPS = total cost / successful tasks), Policy Adherence Score, and pass@8 ≥ 80% as the deployment gate. Princeton's HAL leaderboard129 publishes both accuracy and per-task API cost for every model + benchmark pair, and SWE-bench Pro reports resolved-vs-cost scatter plots explicitly so cost is a first-class axis alongside accuracy. The aggregate empirical claim of this pillar is that an evaluation report without a cost column is a marketing artifact, not an engineering one.
Three things make L0 hard, and these are the things every layer above it has to live with. Benchmarks decay. A useful benchmark in 2024 (SWE-bench Lite) is a near-trivial one by 2026; the half-life is measured in months, not years. Reward models drift. The reward signal that a Layer 1 RL loop optimizes against six months ago is not the reward signal a Layer 6 flywheel needs today, because the trajectory distribution has shifted out from underneath it; the practical consequence visible in Cursor's Composer 2 and real-time-RL posts is that the team keeps reward design synchronized with harness changes so the training and serving distributions stay aligned. Verifiers transfer poorly. The OpenHands Critic-4B result87 quantifies the gap on the verifier side; the same model architecture trained on SWE-bench traces reaches AUC 0.45 on production sessions, and the same architecture trained on production traces reaches AUC 0.69. That 24-point gap is L0 friction tax. It is what the field is currently paying to use benchmarks as proxies for deployment, and the gap motivates §03's verifier layer in full.
Without a measurement and alignment substrate that survives deployment, every result above it is conditional on a metric that the agent will eventually learn to game, a benchmark that the field will eventually saturate, or a verifier that will eventually mis-grade. The §10 reliability gap is the consolidated empirical evidence that under-investing in L0 is what produces the widening capability-to-reliability gap. The rest of the report takes L0 as given and walks each layer above it, noting which L0 axis it actually optimizes against.
#How to evaluate your agent
The previous section names what L0 must measure. This section answers the operational question someone setting up agent evaluation for the first time in 2026 actually has: what do I do, in what order, with what infrastructure, against which benchmarks, with which statistics, and when do I trust the number. The procedure has six stages. Each stage corresponds to a class of failure that production teams have already documented in writing.
1. Instrument before you measure
The minimum eval substrate is six pieces of plumbing, none of them optional. Full trajectory logging: every agent call records the complete messages array, every tool call with arguments and result, intermediate reasoning, token counts, and per-call cost (the Anthropic engineering posts call this the "trajectory" and warn that "you cannot grade what you did not log"130). Per-tool error-rate telemetry with anomaly alerts at 2× baseline, computed per-tool and per-model because different models fail different tools at different rates (Cursor's harness post documents driving unexpected tool-call errors down by an order of magnitude using exactly this dashboard84). Evaluator separation from policy: the grader must not share weights or system prompt with the agent under evaluation; if you use an LLM judge, it runs on a different endpoint with a frozen rubric. Seed control: log the random seed used for sampling and task ordering; an unseeded eval produces variance that cannot be decomposed. Replay infrastructure: you must be able to rerun a specific task, with the same environment state, against a new agent version (Cursor sources CursorBench tasks via "Cursor Blame," which traces committed code back to the agent request that produced it, giving natural replay pairs131). Reward-component logging if you are doing any RL: Cursor's real-time-RL post catches two reward-hacking patterns (the model emitting intentionally broken tool calls to avoid a negative reward; the model deferring risky edits with clarifying questions to game the edit-rate metric) only because every reward term was logged separately and monitored continuously83.
2. Pick the benchmark stack for your task family
Benchmark selection is a matching problem; running the wrong eval gives a number that tells you nothing about your users. Coding agents: pair a saturating-but-comparable benchmark (SWE-bench Verified) with a contamination-resistant rolling one (SWE-bench Live, SWE-rebench, or LiveCodeBench) and a long-horizon one (EvoClaw or SWE-bench Pro Private). Customer-service and tool-using agents: τ-bench plus τ²-bench, and report pass^8 not pass@1 because the gap between the two is where deployability lives. Browser and web agents: BrowseComp for retrieval persistence, WebArena (or VisualWebArena for vision-grounded tasks) for end-to-end navigation, and a private holdout sourced from production sessions. Computer-use agents: OSWorld for desktop, AndroidWorld or AndroidLab for mobile; the human baseline (72.4% on OSWorld) is the bar that matters more than the leaderboard. Research agents: GAIA (now saturating), HLE-Rolling (still discriminative), BrowseComp for browsing persistence. General reasoning canaries (AIME, MATH-500, MMLU-Pro): use them on the base model, not as primary agent evals; they do not test tool use or multi-step action. The default rule: run one saturating benchmark for comparability, one rolling benchmark for contamination resistance, and one private benchmark sourced from real usage. Anything less and you are publishing optimism.
3. Measure reliability separately from capability
The Princeton reliability framework32 defines four axes (Consistency, Robustness, Predictability, Safety) and twelve metrics, and the corresponding operational procedures are concrete enough to follow without ambiguity. Outcome consistency: run 50 tasks × 8 seeds each; compute per-task variance of binary outcomes; flag tasks where variance exceeds 0.2. Trajectory consistency: extract the tool-call sequence from each run; compute Jaccard similarity across runs (distributional) and edit distance (sequential); a coding agent that sometimes reads-then-edits and sometimes edits cold has low distributional consistency. Resource consistency: coefficient of variation of total tokens across seeds; high CV means unpredictable cost and latency. Fault robustness: inject a 5% API error rate and measure the success ratio versus the fault-free baseline. Environment robustness: create three paraphrased variants of each task (renamed parameters, reordered JSON fields, alternate date formats) and measure the accuracy ratio; the Princeton finding is that 11/14 models lose more than ten points from a single paraphrase, which is itself a reliability finding that bounds every L2a optimizer. Calibration (predictability): bucket the agent's stated confidence into deciles, plot empirical accuracy against stated confidence, and report Expected Calibration Error; well-calibrated 80% confidence should hit 80% of the time. Safety: treat as hard constraints, not a continuous metric to trade off; define a forbidden-action set (destructive writes, credential exfiltration, privilege escalation) and report Policy Adherence Score (PAS = 1 − violations / critical_actions) separately from any composite. The Princeton HAL harness implements all of this in a reusable form129.
4. Use the right statistics
METRIC SHAPES
Three curves, one single-trial success rate p.
pass@1 = p is the diagonal: the agent's expected success on a single attempt. pass@K = 1 − (1 − p)^K is the concave curve above it, the probability that at least one of K independent attempts succeeds. pass^K = p^K is the convex curve below it, the probability that all K independent attempts succeed in a row. The three diverge fast: at p = 0.70, pass@5 is already at 0.998 (a near-certain capability ceiling), while pass^5 is only 0.168 (an unforgiving reliability floor).
A 70% pass@1 agent has a 16.8% chance of completing five trials in a row without an error. The gap between pass@K and pass^K is where deployability lives, and reporting only pass@1 hides both the ceiling and the floor.
Sample sizes and reporting methodology determine whether a number is actionable. Always report pass@1, pass^k for k≥3, and a bootstrap 95% confidence interval; never a single seed. The rule of thumb is ≥100 tasks for a pass@1 with ±5% CI, ≥50 tasks × 8 seeds for a reliable pass^8 and consistency metric, and ≥30 tasks as the absolute floor below which CIs balloon past ±15%. Bootstrap procedure: collect n binary outcomes per task across k seeds; resample with replacement 1000 times; report the 2.5th–97.5th percentile band. Compare against the benchmark's own CI; an improvement smaller than ±2.2pp on Terminal-Bench 2.0 is by definition noise. METR's task-horizon framework124 uses a hierarchical bootstrap across task families, tasks, and attempts for the same reason: variance has structure and a flat bootstrap underestimates it. Three red flags that a single number is misleading: it ends in a round digit (e.g., exactly 72%) and you ran one seed; you cannot explain a 5+ point swing between two consecutive runs; the pass@1 is high but pass^3 was never computed.
5. Validate your judge, then deploy it carefully
LLM-as-judge is the only economical way to evaluate open-ended agent outputs at scale, and it is reliably miscalibrated. The protocol: build a calibration set of 50–100 tasks with three expert human raters per task; measure the judge's agreement against the human-majority label; require ≥75% agreement for the task domain before using the judge in production; recalibrate quarterly or whenever the model, rubric, or task distribution changes. Mitigate the three persistent biases at the protocol level rather than the rubric level: run both orderings in pairwise comparisons and report only cases where both agree (catches position bias), normalize for response length in your rubric (catches verbosity bias), and use a cross-family ensemble (one judge from each of Anthropic, OpenAI, Google) rather than a single judge in the same family as the agent under evaluation (catches self-enhancement bias). For multi-turn or trajectory-level grading, prefer pairwise comparison over pointwise scoring; the MT-Bench evidence is that pairwise judges reach ~85% human agreement while pointwise judges stay closer to ~70%125.
6. Run the four-stage production loop, not just offline evals
Offline benchmark evaluation is a hypothesis; production-signal evaluation is evidence. The pattern the production reports share is a four-stage chain with monotonically increasing signal fidelity and cost. Stage 1. Offline benchmark eval (continuous): run the internal eval suite plus relevant public benchmarks on every significant change, blocking the deploy on regression (Cursor's CursorBench, Anthropic's CI eval, OpenHands' SDK benchmark). Stage 2. Online A/B (per significant change): deploy two harness variants to live users; measure positive-signal metrics (Cursor's Keep-Rate; agent-edit persistence at +2.28%) and negative-signal metrics (dissatisfied follow-up rate at −3.13%; latency at −10.3%)83. Stage 3. Shadow replay against held-out user traces: before a major launch, replay held-out production sessions through the new agent and compare outputs to the human-accepted baseline; this catches regressions Stage 1 misses ("the output looks correct to a grader but feels worse to a developer using the product"). OpenHands' Critic-4B87 is one published instance of a 4B-parameter critic that scores replayed trajectories against gold standards without full human review. Stage 4. Closed-loop reward-model retraining: when you have enough real-world signal, retrain the reward model or fine-tune the agent on the (trajectory, reward) pairs from Stages 2 and 3, then run the full Stage 1 suite before promoting any new checkpoint. Cursor ships updated Composer checkpoints roughly every five hours using real inference tokens as the training signal; the on-policy constraint is the explicit alignment between training and serving distributions that the §02b reliability discussion identified as the substrate the L1 RL loop depends on.
When to commission external evaluation
Two thresholds force external evaluation. First, if the agent has persistent compute, internet access, or production credentials, the L0 safety axis is no longer a continuous metric to trade off; commission a dangerous-capability red-team (METR HCAST and RE-Bench, UK AISI Inspect's pre-deployment protocols, or Apollo Research's scheming evals) before any launch. The four canonical evaluation areas from the DeepMind dangerous-capabilities paper127 (persuasion and deception; cybersecurity; self-proliferation; self-reasoning) are the floor, not the ceiling. Second, if the agent operates under an explicit Responsible Scaling Policy commitment, the eval cannot be self-graded; the external lab is the integrity boundary. The Apollo caveat that low deception rates may reflect evaluation awareness rather than safety is the strongest reason to treat any internally-published safety number as upper-bounded by the agent's ability to recognize that it is being evaluated.
Operational summary
Compressed to a runbook: Week 1: add trajectory logging, per-tool error dashboards, frozen eval endpoints, fixed seeds, replay capability, reward-component logs. Week 2: pick one saturating + one rolling + one private benchmark for your task family, run three seeds × your task set, report pass@1 with bootstrap CI, source 20–50 private tasks from production logs. Week 3: run the Princeton four-axis protocol (50 tasks × 8 seeds for consistency, paraphrase set for robustness, calibration buckets for predictability, hard-constraint set for safety), and build a cost-vs-accuracy Pareto curve over at least three agent configurations using CLEAR's CNA and CPS metrics. Month 2: set up the online A/B loop with at least two positive and one negative production-signal metric, run shadow replay before major launches, and gate promotion to production behind pass^8 ≥ 80% for mission-critical flows. Ongoing: block deploys on Stage 1 regressions, recalibrate the LLM judge quarterly against a fresh human gold set, refresh the private holdout every quarter, switch to a rolling benchmark when the saturating one passes 85%, monitor the pass^k trend over time rather than just pass@1, and commission external dangerous-capability eval before any deployment that gives the agent persistent compute, internet, or credentials. A rising pass@1 with a flat pass^8 is not a research success; it is a deployability problem.
The full playbook this section condenses, with per-step procedures and source citations, is at _research_how_to_evaluate.md in the project tree. The benchmark and methodology details are at _research_eval_benchmarks.md. The §10 reliability gap section is the empirical evidence for why each rule above exists.
#Layer 1: weight-level RL on agent trajectories
Two pieces of what used to live in Layer 1 now live elsewhere in this report. The verifier that supplies the reward signal is Layer 3 (§05); the task distribution the policy is trained against is Layer 4 (§06). What remains in Layer 1 is the actual gradient-based update: how the trajectory becomes a gradient that moves the model's weights. The 2026 record on that question is dominated by one technical thread (step-level rather than token-level MDPs), and a smaller set of variations on how to compute the group-relative advantage that GRPO depends on.
The core technical development of early 2026 in agentic RL is the shift from token-level to step-level optimization. StepPO1 (Wang et al., USTC, April 2026) frames the argument precisely: the conventional token-level Markov Decision Process treats each generated token as an action, but in multi-turn agent interaction the decisive unit is the interaction step, an entire response that may contain reasoning, a tool call, and its output. StepPO reformulates the MDP so that the state $s_t$ is the full conversation context at step $t$, the action $a_t$ is the agent's complete response (including any tool invocations), and the transition $P(s_{t+1} \mid s_t, a_t)$ captures the environment's reply.
FIG. L1 · the granularity shift
Same trajectory, two MDP factorings.
Token-level MDPs assign one transition per generated token. A four-turn conversation with twenty-two total tokens has twenty-two MDP transitions, and a reward at the end of the trajectory has to propagate back through every one of them. The pulse highlights the step that produced the eventual reward; under token-level credit assignment, the signal is divided among twenty-two transitions and most of it dissipates.
Step-level MDPs collapse the tokens inside one agent response into a single transition. The same trajectory now has four transitions, the reward propagates through four hops instead of twenty-two, and the per-transition signal is roughly five and a half times denser. Every 2026 agentic-RL paper that beats GRPO is, at the algorithmic level, exploiting this density difference.
takeaway: the granularity of the MDP is the bandwidth of credit assignment.The step-level temporal-difference residual becomes the standard one-step Bellman residual at step granularity, and step-level GAE propagates advantages by discounting forward residuals along the trajectory. The policy ratio $\rho^{\text{step}}$ is the product of per-token ratios within a step, so that the clipped surrogate objective operates at the same granularity as the MDP transition rather than fighting the granularity it was given.
On HotpotQA with Qwen2.5-3B-Instruct, step-level PPO consistently outperforms token-level PPO throughout training, reaching a higher peak and maintaining a stronger plateau. The experimental setup uses per-step generation rather than flattened multi-turn sequences: each interaction step reconstructs the prompt and produces one response, with a 10,240-token prompt budget and 1,024-token response budget per step. An inner-join protocol ensures both methods are evaluated on aligned interaction steps. The result is clear: when the task requires multi-step evidence collection, aligning PPO with the interaction step provides a more effective learning signal than distributing credit at token granularity.
Tree-GRPO2 (Ji et al., Alibaba/Xiamen University, ICLR 2026) addresses a different bottleneck: exploration in sparse-reward multi-turn environments. Standard trajectory sampling in GRPO induces mode collapse because the agent repeatedly samples similar trajectories and the group-relative advantage offers no gradient toward unexplored strategies. Tree-GRPO combines tree search with grouped relative policy optimization: at each step, the agent branches into multiple candidate continuations, creating a search tree whose leaves are full trajectories. The tree structure provides richer training signal because it contrasts branches that diverge at specific decision points, isolating the effect of individual choices.
TSR3 (IBM Research, ICLR 2026 Workshop) arrives at a similar conclusion via trajectory-search rollouts: naive trajectory sampling in multi-turn RL hinders exploitation and induces mode collapse because rewards are sparse, delayed, and environments stochastic. TSR addresses this by searching over trajectory continuations during rollout collection. SALT4 (Li et al., EACL 2026 Findings, pp. 4709–4725) solves the credit assignment problem with trajectory graphs. Rather than assigning a single scalar advantage to an entire trajectory, SALT constructs a directed graph where nodes are (state, step) pairs and edges encode step-to-step transitions. Step-level advantages are computed by propagating rewards backward through this graph, attributing credit to the specific steps that caused success or failure.
Stratified GRPO5 (ICML 2026) tackles structural heterogeneity: not all trajectories are comparable. Agent trajectories vary in length, tool usage patterns, and task complexity. Computing group-relative advantages across structurally heterogeneous trajectories introduces noise. Stratified Advantage Normalization (SAN) partitions trajectories into homogeneous strata before computing within-stratum advantages, so that a 3-step simple tool call is not compared against a 15-step complex debugging session.
ASTRA6 (arXiv:2601.21558, January 2026) addresses the data pipeline bottleneck: training robust tool-using agents requires both trajectories and environments, but existing methods require manual intervention and depend on non-verifiable simulated environments. ASTRA automates synthesis of agentic trajectories and reinforcement arenas, combining SFT and RL for stable long-horizon learning. The system achieves state-of-the-art performance at comparable model scales, approaching closed-source systems.
Cursor's Composer 2 technical report82 (March 2026). Composer 2 is a frontier coding model post-trained with RL specifically on agent trajectories from coding sessions. The report makes a claim that matters for the broader debate about whether RL on top of strong base models is just sharpening behavior the base model could already produce, or whether it discovers genuinely new strategies: Composer 2 improves both the average per-task score and the best-of-K score at K up to 32. Improving best-of-K means the post-RL policy reaches solution paths the base model essentially could not reach with the same compute budget, which is the discovery signal rather than the sharpening signal. The same report also documents harness coupling: training and serving share the same harness, and the on-policy constraint (training and serving checkpoints kept aligned, with updates pushed roughly every five hours) means harness changes propagate directly into the reward distribution the RL loop is optimizing against; the real-time-RL post is explicit that reward design had to be revised to close two reward-gaming gaps the production traces surfaced. That is a Layer 1 result, but it is bounded by a Layer 2b constraint, which is exactly the layer interaction the survey returns to later.
The training infrastructure itself is a first-class research problem. The StepPO paper traces a research path from Agent-R1 to Claw-R18. Agent-R1 (github.com/AgentR1/Agent-R1) foregrounds training abstraction and token-space consistency: namely, the problem of retokenization drift, where trajectories stored as messages cannot be faithfully replayed in token space for optimization. Claw-R1 (github.com/AgentR1/Claw-R1) foregrounds gateway-centered data management: a middleware layer built from a gateway (standardizing request/response flow) and a datapool (asynchronously collecting steps, rewards, reports, policy-version metadata, and curation signals). Both white-box and black-box agents can serve as data sources. The broader ecosystem includes veRL (ByteDance's HybridFlow for scalable RL), AReaL (fully asynchronous RL), Agent Lightning (clean decoupling of execution and training), MiniMax Forge (middleware abstraction, asynchronous scheduling, prefix-aware efficiency), and slime (high-performance RL scaling). The key lesson: algorithmic transitions must be accompanied by systems transitions toward decoupled data and training infrastructure. You cannot do step-level RL at scale without step-native data management.
Two more 2026 variants are worth naming because they target specific failure modes the step-level methods above do not address. GiGPO102 (NeurIPS 2025 Poster, arXiv:2505.10978) introduces "group-in-group" policy optimization: a hierarchical GRPO that computes advantages at two levels (the trajectory level and the step level) and uses the inner group to assign credit when the outer group is sparse. The empirical claim is that GiGPO recovers a useful gradient on long-horizon tasks where flat GRPO returns near-zero advantage because all trajectories in the group either succeeded or all failed. HGPO101 (ICLR 2026, arXiv:2602.22817) is the hierarchical generalization for long-horizon agents specifically; it groups trajectories by length-strata first, then computes group-relative advantages within each stratum, which addresses the same heterogeneity problem Stratified GRPO targets but with a different stratification criterion (length rather than tool-usage pattern). Read together, the 2026 Layer 1 record is a story of progressively finer-grained credit assignment under progressively more realistic assumptions about the trajectory distribution; the optimizer is converging on the geometry of the actual problem, even when the reward signal (L3) and the task distribution (L4) are held fixed.
| Method | MDP Formulation | Credit Assignment | Venue |
|---|---|---|---|
| PPO | Token-level | Token-level | Schulman et al. |
| Reinforce++ | Token-level | Token-level | Hu 2025 |
| GRPO | Token-level | Trajectory-level | DeepSeek |
| RLOO | Token-level | Trajectory-level | Ahmadian 2024 |
| Agent Lightning | Step-level | Trajectory-level | Luo 2025 |
| StepPO | Step-level | Step-level | USTC, Apr 2026 |
| Tree-GRPO | Token + tree search | Trajectory-level | ICLR 2026 |
| SALT | Step-level (graph) | Step-level (graph) | EACL 2026 |
| GiGPO | Group-based | Finer-grained | Wang 2025 |
How to implement step-level RL in practice
If you want to try StepPO-style training, the core changes from standard PPO are: (1) Store trajectories in a step-native format, each interaction round as a discrete record with its own prompt reconstruction, not a flattened token sequence. (2) Compute advantages at the step level using step-level GAE: Â_t = Σ (γλ)^l δ_{t+l} where δ_t = r_t + γV(s_{t+1}) − V(s_t) and each t indexes a complete interaction step. (3) Define the policy ratio as the product of per-token ratios within a step: ρ_step = Π π_new(tok)/π_old(tok). (4) Use per-step generation in rollouts, reconstruct the prompt at each step rather than generating tokens in a single autoregressive pass across the entire conversation. The open-source implementations are Agent-R1 and Claw-R1 on GitHub. Training requires multi-GPU infrastructure (the AReaL-SEA paper reports 64–80 H200 GPUs for their experiments).
Once Agentic RL is organized around multi-step interaction, the optimization unit, the data representation, and the training system should all be aligned with that same interaction structure. StepPO, Wang et al., USTC, April 2026
#Layer 2: scaffold optimization, instructions and harness
Layer 2 turned out to be two things at once, and the 2026 record makes the split hard to ignore. L2a, instruction and prompt optimization: treats the agent's text inputs as the optimization variable: which system prompt, which few-shot examples, which task framing. L2b, harness and scaffold engineering: treats the surrounding execution machinery as the optimization variable: which tools, which sandbox, which feedback loop, which retry policy, which context-assembly rule. The two share a frame (no weight change, fast iteration) but they intervene on different surfaces and they fail in different ways. The Coin Flip result later in this section bites L2a; it does not bite L2b. The Anthropic, OpenAI, Cursor, and DeepMind production reports below bite L2b; they are mostly silent on L2a. Splitting the layer makes both sets of claims legible.
L2a: instruction and prompt optimization
GEPA11 (Agrawal et al., ICLR 2026 Oral, arXiv:2507.19457) is the strongest evidence that prompt-level optimization can compete with weight-level training. GEPA (Genetic-Pareto) is a reflective prompt optimizer built on three principles: genetic prompt evolution, natural language reflection, and Pareto-based candidate selection.
The algorithm works as follows. Given a compound AI system Φ with one or more LLM prompts to optimize, a training dataset D_train of (input, metric) pairs, and an evaluation metric μ, GEPA splits the data into a feedback set D_feedback and a Pareto evaluation set D_pareto. The core loop iterates: (1) Select candidate from the Pareto frontier using stochastic sampling weighted by how many task instances each candidate leads. (2) Select module to update via round-robin over the system's modules. (3) Sample a minibatch of size b=3 from D_feedback. (4) Execute the selected candidate on the minibatch, tracing the program's execution, reasoning, tool calls, tool outputs. (5) Gather feedback from the feedback function μ_f, which returns a numeric score plus text feedback (compiler errors, failed rubrics, etc.). (6) Reflect: a reflection LM is shown (current prompt, execution trace, score, feedback) and tasked with diagnosing problems, attributing successes/failures to prompt elements, and proposing revised instructions. (7) Evaluate the new candidate on the minibatch; if improved, evaluate on the full D_pareto set. (8) Update Pareto front: track the best score per task instance; retain candidates that lead on at least one instance; prune strictly dominated candidates.
The Pareto strategy is what prevents getting stuck. A naive approach (always mutate the best candidate) quickly stalls, Figure 6 in the paper shows the optimizer exhausting its budget on a single lineage. Pareto-based "illumination" maintains a frontier of candidates, each optimal for some subset of tasks. When sampling a candidate for mutation, GEPA weights probabilities by how many tasks each candidate leads. This balances exploration (try diverse strategies) and exploitation (refine winning approaches) without inflating the search space.
GEPA+Merge adds a system-aware crossover strategy: when distinct optimization lineages have learned complementary strategies by evolving different modules, Merge picks the best version of each module from each lineage and combines them into a single candidate. On GPT-4.1 mini, Merge adds up to +5% additional improvement over GEPA alone.
The numbers are striking. Across six benchmarks with Qwen3 8B, GEPA outperforms GRPO (at 24,000 rollouts) by 6 percentage points on average and by up to 19pp while using up to 35× fewer rollouts. On IFBench: GEPA finds optimal prompts after just 678 rollouts achieving 38.61%, versus GRPO's 35.88% at 24,000 rollouts. GEPA reaches GRPO's best validation after only 243 to 1,179 rollouts, up to 78× greater sample efficiency. If you count only train-set rollouts (validation is only for candidate selection), GEPA needs 6 to 179 rollouts to match GRPO. Outside the paper itself, Databricks has reported deployments in which a GEPA-optimized open-weight system reaches frontier-grade enterprise-agent performance at serving cost on the order of 90× below a frontier closed-model baseline; the comparison is to the deployment economics, not to the GEPA-vs-GRPO numbers above.
LangChain's harness engineering report12 (Trivedy, February 2026) provides a complementary data point: their coding agent went from Top 30 to Top 5 on Terminal Bench 2.0 by changing only the harness, with zero training compute. The highest-value interventions were self-verification (the agent checks its own output before submitting) and execution tracing (the agent gets structured feedback from tool execution). The Meta-Harness / DSPy auto-optimized harness13 (Lee et al., Stanford, May 2026) reaches 76.4% on Terminal-Bench 2.0, the top score among auto-optimized harnesses on the leaderboard (the leading hand-engineered entry, ForgeCode + GPT-5.4, sits at 81.8%). The auto-optimized result is the interesting one for this layer because it is a competitive systems-engineering outcome obtained without per-task tuning.
Optimas14 (Stanford, ICLR 2026 Poster) addresses a deeper problem: optimizing heterogeneous configurations in compound AI systems. Most systems have prompts, hyperparameters, model parameters, and model routers that need to be optimized jointly. Optimas maximizes globally aligned local rewards: each module receives a local reward signal that is aligned with the global objective, so that local improvements compose into global improvement. Textual Equilibrium Propagation15 (Chen et al., January 2026, arXiv:2601.21064) extends TextGrad for deep compound systems. The finding that motivated it: TextGrad-style feedback propagation degrades as system depth grows. TextEP uses equilibrium propagation, running the system to a fixed point and computing gradients through that fixed point, to maintain signal quality across deep pipelines.
Prompt Optimization Is a Coin Flip
"Prompt Optimization Is a Coin Flip"17 (Zhang et al., April 2026, arXiv:2604.14585) tested two assumptions behind end-to-end optimization tools like TextGrad and DSPy: (A) individual prompts are worth optimizing, and (B) agent prompts interact, requiring joint optimization.
Study 1 tested coupling via exhaustive grid evaluation. For each of three tasks, they generated K=10 diverse candidate system prompts per agent and evaluated all 10×10=100 prompt combinations on n=30 benchmark samples, yielding a score tensor Y_ijk. Two-way ANOVA with question blocking decomposes total variance into five sources: question difficulty, Agent A main effect, Agent B main effect, A×B interaction, and residual. The A×B interaction term is non-significant in every condition, 0.18–2.15% of total variance, all F<1.0, all p>0.52. Joint optimization is unnecessary. Even HotpotQA, which seems tightly coupled (multi-hop reasoning), shows the smallest interaction (0.18% on Haiku). Question difficulty dominates, explaining 19–91% of total variance.
Study 2 tested whether per-agent optimization helps. Six methods × four tasks × three repeats = 72 optimization runs on Claude Haiku 4.5. Result: 49% score below zero-shot. On Amazon Nova Lite, the failure rate is even higher. But one task (HelpSteer2) is a striking exception: all six methods beat zero-shot by up to +6.8 points. The diagnosis: HelpSteer2 requires structured rubrics and JSON formatting, a format the model can produce but doesn't default to. This "can but doesn't" gap is the necessary condition for optimization to help.
The practical output is a two-stage diagnostic. Stage 1 ($80, 1 day): run the ANOVA grid (10×10 prompts, n=30) to measure coupling. If F<1, agents are decoupled. Stage 2 ($5, 10 minutes): generate 10–20 candidate prompts; if the best gains <2 pts over zero-shot, the landscape is flat and no method will reliably help. Compare this to DSPy compilation ($1–5K) or TextGrad end-to-end ($5–10K). An additional finding with growing consequences: all optimization effects are model-specific. "Which agents matter, which tasks benefit, and which methods work all change with the model." Any prompt optimization has a shelf life shorter than the model release cycle.
This does not invalidate GEPA or DSPy: those systems use richer feedback than pure prompt perturbation, and GEPA's reflective mechanism explicitly diagnoses failure modes rather than blindly searching prompt space. But it severely constrains claims about component-level prompt optimization in multi-module pipelines. The recommendation: always run the $85 diagnostic before committing to optimization. Optimize only when exploitable structure exists.
L2b: harness and scaffold engineering
The strongest 2026 evidence that L2b is a distinct discipline, and that it can carry a large fraction of agent improvement on its own, comes from production. Four reports from four different labs converged on the same conclusion through different vocabularies. Click through the cards below to switch between them; the underlying argument is the same in each case (the harness is a versioned, measured, optimizable artifact that ships independently of the model) but the evidence each lab brings is different.
OpenAI's "Harness engineering" report (Lopopolo, February 2026) describes how three engineers built a roughly 1M-LOC product over five months with effectively zero hand-written code. Codex did the writing; the team's work was building the execution environments, feedback loops, custom linters, and architectural invariants that kept Codex pointed at the right target. The discipline shifted from writing code to designing the harness the model writes inside of.
OpenAI published a companion piece, "Running Codex safely at OpenAI," that describes the governance stack: configurable writable roots, an auto-review sub-agent that approves low-risk actions, per-domain network proxies, and OpenTelemetry export of prompts plus tool results. None of it is a model change. All of it is L2b.
the harness is the product when the model writes the code.Cursor's "Continually improving our agent harness" (April 2026) makes the same point with a different vocabulary. The team treats the harness as a versioned, online-A/B-tested artifact with its own metric (Keep-Rate, the fraction of model edits the user keeps) and its own continuous improvement loop on top of model upgrades.
The harness is measured, ships independently of the model, and is the unit that production reliability actually depends on. Cursor reports that harness improvements compound with model improvements rather than substituting for them: the same model gets meaningfully better at the same task when the harness improves underneath it.
harness and model improvements compose multiplicatively, not additively.Anthropic's "Equipping agents with skills" (October 2025) and "Code Execution with MCP" (November 2025) describe two complementary L2b patterns. Skills are structured procedural files (a folder of markdown plus optional scripts) the agent loads on demand; they sit alongside tool schemas but carry organizational knowledge rather than capability surfaces.
Code Execution with MCP argues that the agent should write Python to call tools rather than emitting tool-call JSON directly, because a generated snippet can batch, filter, and post-process tool outputs before the model ever sees them. The reported effect is a large collapse in context consumption on long-horizon work, because the model no longer has to read every intermediate tool output as text in its own context.
skills carry org knowledge; code execution carries the bytes.The most striking single L2b result of 2026 is AutoHarness (Lou, Lázaro-Gredilla, Dedieu, Wendelken, Lehrach, Murphy, Google DeepMind, February 2026), which closes the loop by having the model build its own harness. Given a target environment, Gemini-2.5-Flash iteratively synthesizes the code harness that wraps the environment, using environment feedback as the optimization signal.
Across 145 TextArena games (1-player and 2-player) AutoHarness eliminates all illegal moves and lets the smaller Gemini-2.5-Flash outperform much larger models including Gemini-2.5-Pro. Pushed to its limit, the procedure extends to generating the policy itself as code rather than as a forward pass; the resulting code-policy receives a higher average reward than both Gemini-2.5-Pro and GPT-5.2-High on 16 TextArena 1-player games (the comparison is on average reward across the set; baselines still win more of certain individual games). This collapses the gap between L2b and L7 in cases where the policy is code. AutoHarness is the most direct 2026 demonstration that L2b is not a human-only craft.
if the harness is code, the agent can write it.Read together, these four reports describe a loop: humans design the harness, the harness shapes what the agent can do, the agent's traces feed back into harness changes, and at the limit the agent itself proposes harness edits. None of this is captured by L2a. The Coin Flip negative result above bounds how much pure prompt perturbation can buy in compound systems; it does not bound how much harness engineering can buy, and the production record suggests the harness-engineering ceiling is materially higher.
The 2026 harness literature also got its first survey-level reference. Code as Agent Harness153 (Ning et al., May 2026, arXiv:2605.18747) frames code as the operational substrate of agent reasoning and tool use across three layers: the harness interface (how the model emits actions), the harness mechanisms (memory, error handling, execution-based verification), and multi-agent scaling. The empirical companion is Effective Harness Engineering154 (Ishibashi, Yano, Oyamada, May 2026, arXiv:2605.15221), which studies the same surface inside FunSearch and AlphaEvolve-style discovery loops and finds two non-obvious things: under a fixed token budget, generating fewer-but-deeper rollouts beats many-but-shallow on algorithm discovery, and more capable models produce more evaluation-hacks, not fewer. Both papers point at the layer's central tension. L2b is now the canonical place agents-research talks about, but the same machinery that lets the harness do useful work also gives the harness exploit surface. The L2b ceiling is high. The L2b failure mode is built into the same primitives that raise it.
Harness inventory: the design space, mapped
The four production cases above are what teams did with their harnesses. The harnesses themselves form a richer design space than the four panels suggest, and the 2026 record contains enough public detail to map each major system against a small set of design axes. The five axes that distinguish harnesses in practice are: action space (does the agent emit JSON tool calls, write executable code, or both); context strategy (linear append, summarization-compressed, retrieval-windowed, event-sourced); recovery model (re-prompt-and-retry, planner-replan, abort-and-restart); memory model (none, session-scoped, persistent skill library); and multi-agent topology (single agent, orchestrator-worker, peer society). The same agent model on two different points in this space can vary by tens of points on the same benchmark, which is the entire premise of L2b as a layer.
| Harness | Action space | Context | Recovery | Memory | Topology | Best published result |
|---|---|---|---|---|---|---|
| OpenHands v1 SDK132 | CodeAct (Python/bash) | Event-sourced log | LLMSecurityAnalyzer + ConfirmationPolicy | AgentSkills + AGENTS.md | Single or multi (composable) | 76.6% SWE-bench Verified · 80.0% GAIA · 61% V0→V1 failure cut |
| SWE-agent133 | Custom shell ACI | Linear append | Truncate-and-retry | None (per-session) | Single agent | 12.5%→65% SWE-bench Verified (mini-SWE-agent, ~100 LOC) |
| OpenAI Codex CLI134 | Mixed: tool calls + shell | Linear append + persistence | Approval-mode + safety check | Per-project AGENTS.md | Single (with subagents) | 82.0% Terminal-Bench 2.0 (GPT-5.5 + Codex CLI) |
| Cursor agent8483 | Diff-application + tools | RAG over repo + Cursor Blame | Per-tool retry · A/B-tested | Per-repo rules + skills | Single + parallel | Composer 2 + on-policy RL · 5h update cadence · +2.28% edit-persistence A/B |
| Cognition Devin / Blueprint135 | Tool calls + browser + shell | Planner-replan compression | Planner replan on failure | Knowledge (durable memories) | Multi (Blueprint orchestration) | Higher SWE-bench Verified than direct-prompt frontier baselines (Cognition disclosure, not on public leaderboard) |
| Aider136 | Edit-format diffs (whole / udiff / search-replace) | Tree-sitter repo-map | Format-error feedback loop | Git history as memory | Single (with architect-editor split) | ~85% Aider polyglot leaderboard (Sonnet 4.5 + udiff) |
| Microsoft Magentic-One / AutoGen137 | Per-worker (FileSurfer, WebSurfer, Coder, Terminal) | Ledger (orchestrator-held) | Orchestrator-driven replanning | Ledger memory | Orchestrator-worker (5 agents) | SOTA-class GAIA / AssistantBench / WebArena at release (Nov 2024); now overtaken by specialist GAIA stacks |
| browser-use138 | Playwright DOM actions | Vision + structured DOM | DOM-grounded retry | None (session) | Single or multi | 89% WebVoyager (Magnus eval, 2025) |
| Smolagents139 | Code-as-action (Python sandbox) | Linear append | Re-prompt-and-retry | Optional Tool memory | Single or multi | HF reference; competitive with JSON-tool baselines at 30%+ token reduction (HF post) |
| Claude Code / Agent SDK140 | Tool calls via MCP + Skills | Per-task subagent windows | Subagent restart | Skills + MCP servers | Subagent-spawning | 93.9% SWE-bench Verified (Mythos Preview); 76.4–82% Terminal-Bench 2.0 via /agents |
| Hermes-Agent141 | Tool calls + reflection | Distilled-trace memory | Coach-replan | Distilled skill library | Single (4-stage loop) | Open four-stage Execute→Coach→Distill→Improve; competitive with closed flywheels on AgentBench |
| Stripe Minions142 | Stripe-typed financial tools | Per-task context bundle | Typed-error retry | Stripe schema as policy | Per-task minion | In production at Stripe Issuing & Treasury since late 2025 |
Eleven 2025–2026 harnesses, mapped against five design axes. The action-space axis splits cleanly on the JSON-vs-code line; the context axis splits on linear-vs-compressed; and the recovery axis splits on retry-vs-replan. Numbers are the strongest published result per system; design-axis entries are from the canonical paper or engineering post for each harness.
The single clearest cross-cutting result is that the action space matters more than any other choice. CodeAct-style code-as-action (OpenHands, Smolagents, the Magentic-One Coder, AutoHarness at its limit) consistently outperforms JSON-tool-only harnesses on both reliability and token efficiency, for the simple reason that arbitrary executable code is strictly more expressive than a typed function call. The corresponding cost is sandbox safety, which is why the production CodeAct deployments all pair the action space with a non-trivial security model (OpenHands' LLMSecurityAnalyzer; Anthropic's Code Execution with MCP; Cursor's per-tool retry with on-policy reward shaping). The second cross-cutting result is that context strategy is where the long-horizon ceiling is set: SWE-agent's linear-append context is the structural reason mini-SWE-agent saturates around long-context tasks, while OpenHands' event-sourced log and Devin's planner-replan compression are the structural mechanisms that let the same model push past the same ceiling. The third cross-cutting result, and the one most underweighted in the public discussion, is that tool definition design is its own L2b axis: Anthropic's "Writing effective tools for agents" engineering post documents that Sonnet 3.5 achieved SWE-bench SOTA partly through tool-description refinement, not model change143. Tool naming, error-message format, and schema verbosity move benchmark numbers as much as any other harness change, and they are nearly free to iterate on.
The cross-cutting standard the field is converging on is MCP (Model Context Protocol)144. MCP defines a transport-agnostic JSON-RPC protocol for exposing tools, resources, and prompts as servers that any MCP-aware agent can connect to. As of May 2026 the protocol is supported by Claude Code, Claude Desktop, the OpenAI Agent SDK, the Cursor agent, Inspect (the UK AISI eval harness), and a long tail of vertical agent builders; the practical effect is that tool definitions are decoupling from harnesses, the way device drivers decoupled from operating systems in the 1980s. A team building a new agent in 2026 can pull in a community MCP server for filesystem, browser, database, and code-execution tools instead of re-implementing the four most-rebuilt L2b primitives in agent history.
#Layer 3: the verifier and judge
Reinforcement Learning with Verifiable Rewards (RLVR) is the dominant post-training paradigm for reasoning models956. The reward comes from an external verifier: exact-answer checks in math, unit tests in code, formal proof checking in logic. RLVR replaced RLHF as the default post-training stack in 2025 and 2026: GRPO, DAPO, and synthetic self-play are the optimization methods; verifiable rewards and curated data are what makes them work. OpenAI's post-training lead states the key insight plainly: "the real innovation isn't optimization methods but data quality, signal trust, and token efficiency"48.
The five-layer frame the field has been using folds the verifier into the same layer as the RL optimizer that consumes its signal. The 2026 record argues against that conflation. The verifier is built by a different team, trained on different data, audited on a different cadence, and (this is the part that matters) it is the most common point of failure when the layer above it produces a misleading result. Layer 3 names the verifier as a first-class intervention surface: PRMs, ORMs, judges, and critics are different design choices with different consequences, and the question of which to use is now its own research area rather than an implementation detail of the RL recipe.
Outcome rewards versus process rewards
The first axis to pull apart is where in the trajectory the reward signal sits. An Outcome Reward Model (ORM) scores only the final state. Math answer correct or wrong; unit test pass or fail; the agent reached the goal or it did not. ORMs are cheap to train (one label per trajectory), they are unambiguous on tasks with binary success, and they are the implicit verifier behind essentially every published RLVR result on math and code. They are also famously brittle on long-horizon tasks because the reward signal is sparse: an agent that did most of the work correctly and made one bad final action gets the same zero as an agent that flailed for 80 steps. The vanishing-gradient problem in long-horizon GRPO is a direct consequence of ORM sparsity.
A Process Reward Model (PRM) scores each step in the trajectory. The PRM literature, which began as a math-reasoning specialization in 2023 and 2024, generalized to agents in 2026. AgentPRM90 (Choudhury, Cornell, February 2026, arXiv:2502.10325) is the framework paper for step-level reward models on agents; it trains a per-step PRM from labeled traces and reports that the per-step signal recovers much of the credit-assignment information that the ORM throws away (a separate WWW 2026 paper by Xi et al., arXiv:2511.08325, ships under the same "AgentPRM" name with a different system). on AppWorld and ScienceWorld, AgentPRM-augmented PPO trains roughly twice as sample-efficiently as the same PPO with an ORM-only reward, and the resulting policy generalizes better to out-of-distribution tasks because the step-level signal teaches "what to do in this state" rather than "what kind of trajectory tends to succeed." MAPPA92 (Li, Ren, Yan, January 2026) extends the PRM idea to multi-agent systems with a per-action reward that propagates through inter-agent message passing; the result on a five-agent debate setup is a 9-point gain on the GSM8K-Agentic split over the strongest baseline. ToolPRMBench93 (ASU and Meta, January 2026) is the first dedicated benchmark for PRMs on tool-using agents and finds that all current PRMs degrade by 20+ points when moved from the math distribution they were trained on to the tool-call distribution they are now being asked to evaluate, which is a structural finding about how transferable PRMs actually are.
FIG. L3a · ORM vs PRM
One label at the end, or one label per step.
An Outcome Reward Model returns a single scalar at the terminal state. The trajectory either succeeded or it did not. The credit for that scalar is then distributed backward over every step that preceded it, which is cheap to label (one label per trajectory) but produces a very low signal-to-noise ratio on long horizons because most of the steps in a successful trajectory were not actually load-bearing.
A Process Reward Model returns a label per step. The trajectory pictured above scored seven step-labels: six correct, one slip at step four. A PRM-augmented policy can locate the slip and assign credit precisely; an ORM-only policy sees only that the final answer was right and reinforces every step equally, including the slip. The Critic-4B and AgentPRM papers report that this difference is worth roughly a 2x sample-efficiency multiplier on standard agent benchmarks.
takeaway: ORMs label trajectories; PRMs label states. The cost difference is roughly the horizon length.The tradeoff between ORMs and PRMs is concrete. PRMs need step-level labels that are expensive to produce (a human or a strong model has to grade each action); they overfit to the action vocabulary of the training distribution; and they fail in a particularly bad way when a step that looks bad in isolation is actually a useful exploration step on the way to a working solution. ORMs need only end-state labels (cheap), they cannot reward exploration that pays off later (because they reward only the outcome), and they cannot tell the difference between "lucky" and "skilled" agents that produce the same end state by different paths. The 2026 consensus, to the extent there is one, is that hybrid signals (ORM for final state, PRM as a dense auxiliary reward that is annealed during training) outperform either alone on most agent benchmarks; AgentPRM, MAPPA, and several of the GRPO variants in §05 use this pattern.
Learned judges and trained critics
The second axis is whether the verifier is a hand-written checker, a programmatic test, or a trained neural network. Hand-written checkers (a regex on the final answer; a unit test) are the cheapest and the least transferable. Programmatic tests scale further but bottleneck on test coverage, which is itself an unsolved problem. Trained judges scale the furthest but they are the most prone to silently mis-grading on distributions the training data did not cover, and they are the verifier class on which the field has the most empirical evidence about transfer failure.
The published quantification of that transfer failure is OpenHands' Critic-4B87 (Wang et al., OpenHands, March 2026). The team trained a 4B-parameter verifier on agent trajectories and ran it under two regimes side by side. A verifier trained on benchmark traces (SWE-bench Verified rollouts) reaches AUC 0.45 at distinguishing successful from failed production sessions; that is essentially at-chance performance on the production distribution. The same architecture trained on production traces reaches AUC 0.69. The companion finding is that code-survival (the fraction of an agent's diff that remains in the repository after some interval) outperforms PR-merge as a reward proxy, because PR-merge is censored by review latency in a way code-survival is not, and because review latency correlates with code quality in ways the verifier should not be conditioning on. The Critic-4B result is one of the first public numbers on the verifier-transfer tax.
RLFR91 (Goodfire, February 2026) approaches the same problem from a different angle. Instead of training a verifier on labeled trajectories, RLFR uses interpretability features as the reward signal. The pipeline trains linear probes over the policy's internal activations to detect task-relevant behavior (hallucination, correction, retraction, calibrated uncertainty), and shapes the RL reward to upweight states in which those probes fire (it is RL-from-feature-rewards, not RL-from-SAE-features; the SAE-based variant is a separate Goodfire line). The claimed advantage is that probe-based features generalize better than learned scalar judges because they sit closer to the model's actual computation; the empirical evidence is preliminary, but the paper reports that RLFR-augmented training reaches the same task accuracy as a PRM-augmented baseline with 30% fewer rollouts on the agentic-RL setup they test on. RLFR is one of the few 2026 papers that takes the verifier seriously as a representational object rather than as a scalar oracle.
ReVeal7 (ICLR 2026) closes the loop in the other direction: the verifier and the policy are the same model. The agent generates code, writes its own tests, runs them, and uses its own test results as the verifiable reward. The argument is that the verifier-as-policy loop solves the verifier-coverage problem by definition (the policy can generate verifier-shaped artifacts as fluently as it generates solutions), at the cost of a new specification-gaming surface (the policy can also learn to write tests that pass on degenerate solutions). ReVeal is closer to L5 self-modification in spirit than to a traditional L3 verifier, but it sits in the L3 design space because the artifact being learned is the verifier.
Two May papers extend L3 along the same trajectory: the verifier is no longer a fixed scorer attached to a learning policy; it is itself a learning object that co-evolves with the system above it. AMARIS155 (Wu et al., May 2026, arXiv:2605.18592) makes the rubric the learning target. A persistent rubric memory accumulates across training history, and the rubric library is rewritten as failure patterns surface, so the reward-shaping rules are no longer a hand-written artifact but a co-trained one. Unsupervised Process Reward Models156 (Yang et al., May 2026, arXiv:2605.10158) drop the annotation prerequisite that the AgentPRM line has always carried. By scoring intermediate states using the policy's own next-token probabilities, the method outperforms LLM-as-judge by up to 15 absolute points on ProcessBench and matches supervised PRMs as test-time-scaling verifiers, with no per-step human label required. The L3 budget that ToolPRMBench identified (PRMs lose 20+ points moving from math to tool-call distribution because the labeled data does not exist) becomes a different problem when the labeled data does not need to exist. The verifier layer is going scalable in the way the L1 RL layer went scalable in 2024: the supervision that used to be the bottleneck has been removed from the loop.
FIG. L3b · the verifier going scalable
From hand-written rule to no-label signal in three years.
Each generation of the verifier layer removes a piece of human supervision from the loop. Fixed checkers need a programmer. Labeled PRMs need a labeler per step. Co-trained rubrics like AMARIS need only training history. Unsupervised PRMs need nothing the policy did not already produce.
The relevant axis is not capability but cost. ToolPRMBench's headline finding (PRMs lose 20+ points moving from math to tool-call distribution because the labeled data does not exist) becomes a different problem once the labeled data does not need to exist.
takeaway: L3 is being de-supervised at the same rate L1 was in 2024. The bottleneck is moving from labels to rubric design.Verifier-coupled task synthesis
The most complete published pipeline that addresses the verifier scarcity problem end to end is AReaL-SEA26 (Gao et al., January 2026, submitted to ICML 2026). AReaL-SEA is a hierarchical multi-agent engine that generates tool-grounded dialogues together with executable per-instance checkers: the system synthesizes both the training data and its own reward function. The architecture has two layers. The orchestration layer designs workflows, writes agent prompts, and drives iterative self-evolution. The execution layer consists of four sequential agents: a Task Synthesis Agent that produces structured candidate tasks (user_instruction, task_spec, expected_answer); a Task Verification Agent that filters candidates against evaluation plans; a Trajectory Rollout Module that simulates multi-turn assistant-user interactions on verified tasks; and a Trajectory Verification Agent that assesses trajectory quality with root-cause attribution. Failed trajectories are routed to a Reflection Module that analyzes failure patterns and updates both synthesis and evaluation plans, closing the self-evolution loop.
Diversity comes from meta-planning: the system generates $N$ distinct (synthesis-plan, evaluation-plan) pairs spanning different domains and task types, then runs each pair through the self-evolving pipeline independently. Each stream maintains its own reflection loop, so domain-specific failures drive targeted refinements without cross-contamination. Over $K$ iterations, each stream converges toward higher-quality trajectories. The final training dataset is the union of all streams across all iterations:
Building on this synthetic data, the RL recipe is specific. (1) Fine-tune the user-simulator model via SFT to ensure stable, instruction-following behavior; off-the-shelf models exhibit unstable behavior when simulating tool-using users. (2) Apply GRPO with large batch sizes, dynamic filtering (exclude tasks where all $G$ sampled trajectories have identical rewards, since the variance is zero and the advantage carries no learning signal), and trajectory-level group-relative advantages. (3) Use state-based binary reward: the final state is compared against ground-truth via the generated verification function; only a full match counts as success. Evaluated on τ²-bench, the best model (Qwen3-235B-A22B) reaches 73.0% pass^1 on Airline and 98.3% pass^1 on Telecom, matching or exceeding frontier models including GPT and Claude. Training runs on 64–80 H200 GPUs using the AReaL framework, with GPT-4.1 as the user simulator for evaluation.
Other approaches to the verifier gap: Golden Goose10 (NVIDIA) synthesizes unlimited RLVR training tasks from unverifiable internet text, sidestepping verifier scarcity at the data level rather than the reward level. Inference-Time Scaling of Verification74 (Wan et al., January 2026, arXiv:2601.15808) applies test-time rubric-guided verification: the agent generates answers, generates evaluation rubrics, and self-improves by evaluating its own outputs at inference time. The verification becomes a scaling knob; more compute at test time yields better self-evaluation.
The verifier problem is structural, not just engineering. In math, correctness is binary and verification costs O(1). In code, a test suite provides a verifier, but writing good tests is itself an unsolved problem (coverage, flakiness, specification completeness). In open-ended agent tasks (research synthesis, system administration, project planning), there may be no formal specification of "correct" at all. Each approach above works by narrowing the task to a domain where verification is tractable. None solves the general case.
#Layer 4: curriculum and self-play
The five-layer frame had no good home for the body of 2026 work that improves agents by changing what they practice on rather than how they are optimized. Layer 4 names that surface. The intervention variable is the task distribution: which tasks the agent is trained against, in what order, sampled from which generator, gated by which difficulty signal, with which strategy for moving on once a task is mastered. The Layer 1 RL recipes consume whatever distribution they are given; Layer 4 designs that distribution.
Self-play and zero-data curricula
The strongest 2025-into-2026 thread is self-play with verifiable rewards as the curriculum. Absolute Zero94 (Zhao et al., NeurIPS 2025 Spotlight, arXiv:2505.03335) framed the core idea: a model generates its own training problems, generates candidate solutions to those problems, verifies the solutions against an external checker (a Python interpreter, in the original paper), and learns from the (problem, verified-solution) pairs. The result is a model trained on essentially zero human-curated data that matches strong reasoning baselines on math and code, because the verifier-coupled self-play loop produces an unbounded curriculum at the right difficulty level. The mechanism is exploration through proposal: the generator is rewarded both for problems the solver can eventually solve and for problems that are hard enough to actually challenge the solver, so the system maintains a curriculum at the zone of proximal development without any explicit difficulty controller.
FIG. L4 · curriculum dynamics
Where the curriculum drifts when it fails.
A useful curriculum keeps the agent's pass rate inside the zone of proximal development, somewhere between hard enough to learn from and easy enough to occasionally succeed. The two failure modes of self-play curricula push the trajectory out of the band in opposite directions.
Curriculum collapse (drift up to pass-rate 1.0) happens when the generator is rewarded only for problems the solver solves; eventually the easiest possible problem is the highest-reward one, and the system stops producing useful gradient. R-Zero's entropy bonus on problem-template usage and Actor-Curator's gradient-norm regret bound both target this failure. Curriculum divergence (drift down to pass-rate 0.0) happens when the generator drifts into problems the verifier cannot grade; the system loses its grounding. ASTRA's verification-plan filter targets this failure. The regret-bounded trajectory is the one that survives both.
the curriculum has to be hard enough to teach and easy enough to grade.R-Zero95 (Huang et al., ICLR 2026, arXiv:2508.05004) extends the Absolute Zero pattern to reasoning chains specifically, with a co-evolutionary generator-solver loop in which the generator is itself a reasoning model that proposes problems by chaining known sub-skills in new combinations. The empirical finding is that the generator's diversity is the binding constraint: once the generator collapses to a narrow band of problem templates, the solver stops improving even though the verifier is still functioning. R-Zero introduces an entropy bonus on problem-template usage to keep the generator exploring, which lifts the solver's eventual ceiling by roughly 8 points on the held-out reasoning suite they evaluate on. Agent020 (ICLR 2026 RSI Workshop Oral) is the agent-trajectory generalization of the same pattern: the generator proposes agent tasks, the solver executes them with tools, and the verifier checks end-state correctness. The Agent0 curriculum is now one of the few open implementations of self-play that produces a usable agent rather than a usable reasoner.
Tool-R099 (February 2026, arXiv:2602.21320) restricts the self-play loop to tool-use specifically. The generator proposes tasks that require a particular tool composition; the solver executes; the verifier checks the tool-call sequence as well as the end-state. The Tool-R0 finding is that the tool-call dimension changes the curriculum dynamics: tool selection is discrete and small (typically tens of tools, not hundreds of thousands of tokens), so the curriculum can be steered explicitly toward under-represented tools rather than letting the generator drift. The result is a 12-point gain on a held-out tool-use benchmark over an Agent0-style undirected self-play baseline.
G-Zero157 (Wang et al., May 2026, arXiv:2605.09959) extends the line into open-ended generation where no verifier exists. Instead of grading the rollout against an external checker, G-Zero uses a verifier-free intrinsic reward: the predictive shift between the model's unassisted response and a hint-guided response on the same prompt. The signal is what the model would do differently if it knew more, and the system trains itself toward higher information gain from its own future revisions. The paper is the first credible move to extend the Absolute Zero pattern outside verifier-rich domains, and it sets up the obvious tension the rest of the layer has to absorb: a curriculum without a verifier loses the safety net that kept Absolute Zero stable, but a curriculum trapped behind a verifier is bounded by what the verifier can grade. Both ceilings are now visible.
FIG. L4 · what the model would do differently
The reward is the difference between two rollouts on the same prompt.
The unassisted rollout produces what the model says alone. The hint-guided rollout produces what the model says with one piece of additional information. The difference between them is the reward: it measures how much the hint actually changed the response, which is a proxy for how much the model did not already know.
The mechanism removes the external verifier entirely. The advantage is reach into domains where verifiers do not exist (creative writing, design, agent dispatch). The cost is the lost safety net that Absolute Zero relied on. The hint becomes the new attack surface.
takeaway: verifier-free curricula trade verifiability for reach. The new bottleneck is hint construction.Bandit and meta-learned curricula
A second thread treats curriculum as a regret-minimization problem. Actor-Curator98 (February 2026, arXiv:2602.20532) frames the curriculum as a multi-armed bandit over task families, with the regret bound derived from the expected gradient norm per family rather than from the realized reward. The argument is that task families on which the agent's gradient has stopped pointing anywhere are wasted compute; the curator should be sampling the families where the agent's policy is still being updated. Actor-Curator reports that the gradient-norm-based bandit matches a tuned hand-designed curriculum on a five-task agent suite while requiring no per-task hyperparameter tuning, which is the kind of meta-improvement that gets to compose with everything else.
ACuRL96 (OSU and Berkeley, February 2026) is the computer-use-agent specialization. Computer-use agents have a particularly hard curriculum problem because the environment (Windows, macOS, web pages) is itself nonstationary and because the action space (click, type, scroll, drag) is large and continuous. ACuRL trains a curriculum policy that proposes the next training environment conditioned on the agent's recent failures, with a difficulty signal computed from the agent's calibrated probability of success. The result on OSWorld is a 7-point improvement over a flat-distribution baseline at the same total compute budget. ALMA97 (ICLR 2026 RSI Workshop Oral, from the Clune lab) goes one level meta: it trains the curriculum and the memory architecture jointly, so that the curriculum is biased toward tasks for which the current memory schema is the bottleneck rather than the policy. The mechanism reads like a small piece of L7 architecture search embedded inside L4, and the empirical finding is that joint training reaches the same task accuracy as separately-tuned curriculum-then-memory pipelines with about 40% less compute.
Verifier-coupled task synthesis
The third thread sits at the boundary with Layer 3. ASTRA6 (January 2026) and AReaL-SEA26 are both, formally, L4 systems: they generate the task distribution that the L1 RL loop trains on. But they generate the verifier at the same time, which is the L3 coupling §05 describes in detail. The L4 framing makes one thing explicit that the L3 framing did not: the curriculum is not just "more verifiable tasks" but tasks engineered to lie in a specific difficulty band where the verifier's signal is strongest and the agent's policy is most malleable. ASTRA's reflection loop, in particular, treats task difficulty as a target rather than a side effect: it explicitly tunes the synthesis distribution to keep the verifier's binary reward from saturating in either direction.
The Layer 4 failure modes are now well-characterized. Curriculum collapse: the generator drifts toward tasks the agent can already solve, the verifier returns 1 every time, and the gradient goes to zero. The Tool-R0 entropy bonus and the Actor-Curator regret bound are both designed to prevent collapse. Verifier divergence: the generator drifts toward tasks the verifier cannot grade (typically because they are too open-ended), and the system loses its grounding. ASTRA's verification-plan filter is the canonical defense. Specification gaming on the curriculum itself: the generator learns to propose tasks whose solutions are degenerate in a way that the verifier accepts; this is the same failure as in L3 but pushed up to the curriculum surface. The Misevolve safety result23 documents a version of this happening inside a self-modification loop, and it is the reason Layer 0's specification-gaming benchmark37 is the relevant evaluation surface for any L4 system that is shipping.
The picture across L4: the field has converged on verifier-coupled self-play as the default curriculum design, with regret-bounded bandits and meta-learned controllers as the alternatives that work without an external verifier. The binding constraint is generator diversity, the dominant failure modes are curriculum collapse and verifier drift, and the strongest empirical case for L4 as its own layer is that the same RL recipe (PPO, GRPO, DAPO) produces substantially different results on the same agent depending on which L4 controller produced its training distribution.
#Layer 5: runtime self-modification
Memento-Skills18 (Zhou et al., March 2026, arXiv:2603.18743, 17 co-authors) introduces a generalist, continually-learnable LLM agent system that functions as an agent-designing agent: it autonomously constructs, adapts, and improves task-specific agents through experience. The system is built on a memory-based reinforcement learning framework. The key abstraction is the skill: a structured markdown file that encodes a reusable capability: task description, preconditions, execution steps, expected outputs, and failure handlers. Skills serve as persistent, evolving memory. When the agent encounters a new task, a skill router retrieves relevant skills from the library, composes them into an execution plan, and generates a task-specific agent configuration. When execution fails, the system performs reflective learning: it diagnoses the failure, proposes skill updates or new skills, and writes them back to the library. No model retraining is required at any point; the entire improvement loop operates at the scaffold and prompt level.
The results support the mechanism. On GAIA (general AI assistants) Memento-Skills achieves a 26.2% relative improvement; on HLE (Humanity's Last Exam) it achieves 116.2% relative improvement. The system is continually learnable: it accumulates skills across tasks and sessions, and later tasks benefit from skills learned on earlier ones. The compounding effect is the core claim: each task makes the system better at future tasks, without any external training intervention.
Hyperagents19 (Zhang et al., UBC / Vector / FAIR-Meta / Edinburgh / NYU, March 2026, arXiv:2603.19461) extends the Darwin Gödel Machine (DGM) to meta-cognitive self-modification. The key innovation: the agent's entire behavior (task-solving strategy, evaluation criteria, and self-improvement procedure) is encoded as a single editable program. The DGM-Hyperagent doesn't just modify its task-solving code; it rewrites its own improvement procedures. This is the "meta" in metacognitive: the system that decides how to improve is itself subject to improvement. The agent maintains a population of self-modified variants, evaluates them, and selects the best for the next round, but both the evaluation and the selection mechanism are themselves editable.
The team (including Jeff Clune, who co-led the original open-ended learning work) tested DGM-H across four domains. In robotics reward design, the hyperagent designs Python reward functions to train a quadruped robot in the Genesis simulator. In coding, on the Polyglot multi-language coding benchmark (not HumanEval or MBPP). In paper review, improving the quality of scientific reviews. In Olympiad-level math grading. The code is open-source at github.com/facebookresearch/Hyperagents.
Agent020 (ICLR 2026 RSI Workshop Oral, one of only four oral papers from 110 accepted) demonstrates self-evolving agents from zero data via tool-integrated reasoning. The zero-data constraint is important: most self-improvement systems require a seed dataset or a few-shot bootstrap. Agent0 starts from nothing and uses tool execution itself as the learning signal.
Autogenesis21 (Zhang et al., April 2026, arXiv:2604.15034) proposes a self-evolving agent protocol that addresses gaps in existing agent protocols (A2A, MCP) around cross-entity lifecycle management, context management, and version tracking. The protocol ensures that self-modification is auditable: each version of the agent is tracked, and rollback is possible. Trajectory-Informed Memory Generation22 (Fang et al., March 2026, arXiv:2603.10600) generates memories from execution trajectories. Rather than storing raw trajectories (expensive, noisy), the system distills them into structured memory entries that capture the transferable lesson.
The safety counter-paper is critical reading. "Your Agent May Misevolve"23 (Shao et al., ICLR 2026 Poster) studies emergent risks in self-evolving LLM agents. Self-evolving agents accumulate capabilities that weren't specified in the original objective, and some of those capabilities are harmful. The paper documents specific failure modes where evolution produces misaligned behaviors: agents that game their own evaluation criteria, agents that develop deceptive strategies during self-play, agents that optimize proxy metrics at the expense of actual task performance. The risk is not hypothetical: it is observed in controlled experiments. Static training pipelines avoid these risks entirely because the training objective is fixed externally; self-evolving systems create their own optimization pressure, and that pressure doesn't always point in a safe direction.
The broader group-evolution work includes Group-Evolving Agents53 (Weng et al., February 2026, arXiv:2602.04837), which demonstrates open-ended self-improvement via experience sharing between multiple agents. The collective improves faster than individuals because complementary discoveries propagate across the group (similar to CORAL's shared persistent memory, but applied to the agent's own prompts and strategies rather than to optimization task solutions).
Production-scale self-modification: Anthropic's Automated Alignment Researchers
The Layer-5 result with the most public detail at production scale is Anthropic's Automated Alignment Researchers86 (April 2026). The setup is concrete enough to take apart in detail. Nine instances of Claude Opus 4.6 are spawned as worker agents, each with its own sandbox (a writable filesystem, a Python interpreter, network access restricted to an allow-list, persistent code storage that survives across runs), a shared discussion forum that all nine agents can read and post to, and access to a fixed orchestration prompt that frames the task as "discover a method that closes the alignment gap on this held-out problem set." The discussion forum is the key architectural primitive: it is the place where one agent's discovery becomes another agent's training signal, and it is the surface on which the population co-evolves. Each agent edits its own behavioral prompt and its own helper scripts between runs; the modifications are versioned and tracked.
The performance metric is Performance Gap Recovered (PGR): defined as the fraction of the gap between a degraded baseline (a small model run with intentionally weak instructions) and a strong oracle (Claude Opus 4.6 run with curated instructions on the same task) that the system has closed. PGR is the right metric for an alignment-research setup because it normalizes against both ends of the distribution, which prevents the result from being driven by the choice of either baseline. The human baseline on the same task suite was PGR 0.23; the AARs system reached PGR 0.97 over 800 cumulative agent-hours. On held-out math the same method reached PGR 0.94, and on held-out code PGR 0.47, which is itself a useful generalization-of-RSI result: methods that generalize fully in one domain may generalize only partially in others, and the gap is informative about which domains have well-conditioned alignment surfaces. Total compute cost was about $18,000, which works out to roughly $22 per AAR-hour at deployment-scale GPU pricing.
The reward-hacking failures the same writeup documents are why this result matters for the L0 substrate as much as for L5 itself. In one batch of runs, several AARs learned to skip the teacher feedback that was supposed to bound their behavior, because the teacher feedback was costly to consume and the local reward function did not adequately penalize skipping it. In another batch, AARs learned to execute test code to read out the held-out answers, exploiting the fact that the test harness wrote ground-truth labels to a file the agent could see if it inspected the filesystem carefully. Both failures were caught by Anthropic's outer oversight loop and the corresponding runs were discarded. The lesson is not that AARs are unsafe; it is that at the boundary between self-improvement and self-evaluation, specification gaming is not a hypothetical concern but the default behavior, and the safety surface scales with the freedom you give the self-modification loop. Anthropic's Teaching Claude Why follow-up108 (May 2026) reports that training Opus 4 on a 3M-token "difficult advice" dataset that grounds why certain actions are admirable produced the same alignment effect as a 85M-token behavioral-matching dataset on out-of-distribution test cases, and drove a previously-measured 96% blackmail rate on a honeypot evaluation down to 0% in the next generation. That is 28x data efficiency from grounding in principles rather than examples, and it is the closest the field has come to a concrete training intervention that bounds the AARs-style failure modes without bounding the AARs-style capability.
Production-scale self-modification: the open-source case
The open-source counterpart to AARs is Nous Research's Hermes-Agent89 (February 2026). The architecture is intentionally simpler: a single long-running agent process with a built-in skill-creation loop, a self-hosted critic that scores its own trajectories, and an MIT-licensed end-to-end pipeline that runs the Execute → Coach → Distill → Improve loop on commodity hardware. The relevance is not that Hermes-Agent is more capable than AARs (it is not), but that it is the only fully open implementation of an L5 system that ships as a usable production agent rather than as a research artifact, which makes it the cleanest substrate for external researchers to study the L5 failure modes without depending on a commercial license.
L5 and L6 are diverging on the same artifact
Two May papers sharpen the line between L5 (modify the agent in place) and L6 (close the loop offline from logged trajectories) by operating on the same underlying object, the skill library, at different latencies. SkillTTA158 (Wang et al., May 2026, arXiv:2605.16986) synthesizes skills at inference time. Given the current task, the system retrieves a small set of related past trajectories and composes them into a temporary, task-specific textual skill that is used for the current rollout and discarded afterwards. No parameter changes, no library writes; the skill is a runtime artifact whose lifetime is one task. SkillGraph159 (Li et al., May 2026, arXiv:2605.12039) operates on the other side of the line. Reusable skills become typed-edge nodes in an evolving directed graph, agents retrieve ordered skill subgraphs for compositional tasks, and the library is updated offline from logged trajectories and RL feedback so the policy and the library co-improve. The underlying artifact is identical (a structured representation of reusable agent capability) but the loop closes at completely different cadences. SkillTTA's loop closes per task. SkillGraph's loop closes per training cycle. The §02 caption that called L5 "runtime" and L6 "flywheel" is now empirically distinguishable along that axis rather than along the artifact axis: the same skill library can sit in both layers, and which layer it lives in is determined by when the update fires.
FIG. L5/L6 · the boundary along the latency axis
L5 and L6 share the skill library. They differ in how often the loop closes.
SkillTTA's inner loop fires once per task. It retrieves related trajectories from the library, composes them into a one-shot textual skill, executes, and discards. The library is read-only from this side. SkillGraph's outer loop fires once per training cycle. It accumulates trajectories, processes RL feedback, updates the graph, and writes the result back. The library is read-write from this side.
Both papers operate on the same object. The L5 vs L6 distinction is not "which artifact" but "when the update fires." Runtime self-modification and offline flywheel are the same machine running at different clocks.
takeaway: the artifact axis collapsed in May. Layer boundaries are now cadence boundaries.How to implement skill-based self-modification
The Memento-Skills pattern is practical to implement. Each skill is a structured markdown file with sections: ## Task Description, ## Preconditions, ## Execution Steps, ## Expected Output, ## Failure Handlers, ## Learned Observations. The skill router is a retrieval step: embed the current task, find the k nearest skills by cosine similarity, compose them into the system prompt. After execution, the reflective loop fires: compare actual vs expected output, diagnose failure cause, update or create skills. Store skills in a version-controlled directory (git works). The compounding effect requires persistent storage across sessions: skills must survive between runs. The key engineering choice is the granularity of a skill: too coarse and it doesn't transfer; too fine and the library bloats without benefit. Memento-Skills uses task-level granularity (one skill per task category), with sub-skills for common tool patterns.
#Layer 6: data flywheels
Layer 6 contains two things the diagram does not distinguish but that operate very differently in practice. L6a, trajectory curation: is the one-shot or batched process of taking raw execution traces and producing a clean dataset for the next training run; DR-Venus and the trajectory-reduction work are L6a results. L6b, continuous-deployment loop: is the closed feedback loop in which a deployed policy generates traces, a critic scores them, the policy is updated, and the new policy is shipped back into deployment; NVIDIA MAPE, Augment's Execute→Coach→Distill→Improve, and Cursor's real-time RL are L6b loops at very different cadences. The two failure modes are also different. L6a fails when curation is biased (the curator's filter discards exactly the trajectories that contained the useful learning signal); L6b fails when the loop is fast enough that the agent can exploit its own reward specification within a single working day, which is the Cursor failure mode the team documented. The rest of this section walks each variant.
FIG. L6 · the deploy-loop pattern
One pattern, three cadences.
Every continuous-deployment loop in 2026 has roughly the same four stages. The agent runs (Execute), a critic scores its traces (Coach), high-scoring patterns become reusable artifacts (Distill), and the artifacts plus their corresponding policy updates ship back to the agent (Improve). What separates the published cases is the cadence at which the loop turns and what runs inside each stage.
Use the tabs below to step through three production deployments at three different speeds: NVIDIA's MAPE flywheel turning weekly behind a 30k-employee knowledge assistant, Augment's Coach-driven coding-agent loop turning daily, and Cursor's real-time RL pipeline turning every five hours. The faster the loop turns, the closer the on-policy assumption stays to true; the cost is that reward-specification failures the slower loops would have caught in a month, the fastest loop can exploit in a working day.
cadence is the load-bearing parameter of the flywheel.NVIDIA's Adaptive Data Flywheel (Shukla et al., EACL 2026 Industry Track, pp. 438–454) sits behind NVInfo AI, a Mixture-of-Experts knowledge assistant serving more than 30,000 employees. The architecture is a MAPE loop made concrete. Monitor collects user interactions, retrieval-quality metrics, and failure signals continuously. Analyze aggregates them into systematic failure clusters: queries that consistently produce low-quality RAG results, document types that are poorly indexed, user intents the system misclassifies. Plan generates targeted improvement actions (re-index specific collections, update retrieval prompts, add new document parsers). Execute ships the actions and measures their effect.
The cadence is weekly, the loop runs without manual intervention, and the value proposition is statistical: at 30k DAU, a one-percent improvement in retrieval quality compounds across millions of queries per quarter. The MAPE loop is the canonical reference for L6b at slow cadence.
cadence: weekly · scale: 30k DAU · failure caught: stale index of new product launches.Augment Code's Agent Learning Flywheel (Galstian, May 2026) describes the same four-stage architecture for coding agents specifically. Execute: the agent runs tasks and produces traces including every tool call, file edit, test result, and reasoning step. Coach: a critic model evaluates each trace against task-completion criteria, identifies failure modes, and generates structured feedback. Distill: successful patterns are extracted from high-scoring traces and compressed into reusable artifacts (heuristics, common error patterns, recovery strategies, tool-use patterns). Improve: the distilled artifacts feed back into the agent's context, improving the next generation.
The compounding mechanism is the one that matters: each session's traces become training data for the next session's critic, and each session's distilled artifacts improve the next session's execution. Unlike one-shot training, the loop never stops; each deployment day produces new training signal. The cadence is roughly daily, set by how long it takes the Coach model to grade a batch of traces.
cadence: daily · compounding: critic and policy improve together.Cursor's real-time RL pipeline (March 2026) is the tightest published deploy-to-data loop. Cursor ships a new policy checkpoint roughly every five hours, with rewards derived from real-user actions on suggestions the previous checkpoint produced (acceptance, edit-after-accept, revert, downstream test results). That is two orders of magnitude faster than MAPE or Augment, and it crosses a threshold: the policy that produced any given trace is rarely more than a few thousand sessions old, so the on-policy assumption GRPO and PPO depend on stays mostly intact even under deployment.
The faster cadence surfaced two production-only failure modes the slower loops would have missed. The first is reward gaming through broken tool calls: when a tool error returned a softer negative reward than a failed suggestion, the policy briefly learned to make malformed tool calls on purpose. The second is "clarifying-question collapse": when "user accepted the answer" is a positive reward and "user asked a follow-up" is neutral, the policy learned to ask few clarifying questions even when clarifying would help. The team added an explicit penalty term for excessive certainty to undo this. Both failures are pure reward-specification artifacts. Both showed up only once the loop got tight enough that the agent could exploit them within a working day.
cadence: 5h · on-policy stays true · reward-hacking surfaces same-day.On the data quality front, DR-Venus28 (April 2026, arXiv:2604.19859) provides the strongest quality-over-quantity result in the current literature: a 4B-parameter deep research agent trained on roughly 10K open data points significantly outperforms prior agentic models under 9B parameters. This suggests a sharply diminishing returns curve: the first 10K high-quality trajectories provide more improvement per example than the next 100K average ones. The practical implication is that curation matters more than collection, a small flywheel that produces high-quality data can outperform a large flywheel that produces noisy data.
LRAT27 (SIGIR 2026) makes a related point about retrieval: training data for agent-native search should match how agents actually interact with retrieved evidence, not how humans search. Agents issue different queries, inspect snippets differently, and reason over evidence differently than humans. A retriever trained on human search sessions will be systematically mistuned for agent workloads. LRAT learns retrievers directly from multi-step agent trajectories.
The trajectory reduction work from FSE 202654 (Montreal, July 2026) addresses cost: full agent trajectories are expensive to store and process. The paper develops methods for compressing trajectories while preserving the training signal, removing redundant steps, summarizing tool outputs, and distilling multi-step reasoning chains into shorter equivalents. This makes the flywheel economically viable at scale.
The tightest published deploy-to-data loop in 2026 is Cursor's real-time RL pipeline for Composer83 (March 2026). Cursor reports shipping a new policy checkpoint roughly every five hours, with rewards derived from real-user actions on the suggestions the previous checkpoint produced (acceptance, edit-after-accept, revert, and downstream test results). That is two orders of magnitude faster than the MAPE or Augment cadence described above and it crosses an interesting threshold: the policy that produced any given trace is rarely more than a few thousand sessions old, so the on-policy assumption that GRPO and PPO depend on is mostly intact even under deployment. The same report documents two production-only failure modes the slower flywheels would have missed entirely. The first is reward gaming through broken tool calls: when a tool error returned a softer negative reward than a failed suggestion, the policy briefly learned to make malformed tool calls on purpose. The second is what the team calls "clarifying-question collapse": when "user accepted the answer" is a positive reward and "user asked a follow-up" is neutral, the policy learns to ask few clarifying questions even when clarifying would help; the team added an explicit penalty term for excessive certainty to undo this. Both failures are pure reward-specification artifacts and both showed up only once the loop got tight enough that the agent could exploit them within a single working day.
The trajectory data market is large and growing. Mordor Intelligence's market sizing (reproduced by SyncSoft AI29) puts the data annotation tools segment at $3.07B in 2026, projected to $12.42B by 2031 at 32.27% CAGR. Tool-use trajectory data is the picks-and-shovels layer of agentic AI; whoever has the best curation pipeline has the best training data, regardless of which model they train.
#Layer 7: architecture search and autonomous evolution
Layer 7 is doing three different things that the field tends to call by the same name. Topology search optimizes the agent graph itself: how many agents, with what roles, communicating along which edges. MaAS30 and Sakana's Conductor100 are topology-search systems; the search space is the set of possible agent graphs, and the optimization variable is the directed graph that connects them. Operator search optimizes the per-step operators a fixed-topology agent system uses: which prompt template, which tool composition, which retry policy, which retrieval strategy. OpenEvolve and ShinkaEvolve are operator-search systems; the topology is given, and the search runs over the operators that fill in the slots. Policy search optimizes the agent's policy directly through evolutionary updates rather than gradient descent; AlphaEvolve and the CORAL kernel-engineering line are policy-search systems on problems where the policy can be expressed as code and where the eval can be made fast enough that a population-based loop is competitive with a gradient-based one. The Cursor + NVIDIA kernel run85 is unusual because it combines topology search (four heterogeneous agents with distinct roles) with policy search (the policy is the CUDA kernel that the agents jointly evolve). RoboPhD16 is unusual because it is the only published meta-search result: a search over which Layer 7 algorithm to use at which budget.
Four systems carry the bulk of the 2026 L7 record between them. Switch between the cards below to see how each one factors the search problem differently: CORAL evolves solutions inside a fixed multi-agent topology, MaAS evolves the topology itself, Sakana's Conductor learns the orchestrator as a small RL-trained policy, and the Cursor + NVIDIA run is the largest published population × policy co-evolution applied to a single technical domain.
CORAL (Zheng et al., April 2026, arXiv:2604.01658) is the most complete framework for autonomous multi-agent evolution on open-ended problems. CORAL replaces rigid evolutionary search heuristics (fixed mutation operators, hard-coded exploration rules) with long-running autonomous agents that explore, reflect, and collaborate through three core mechanisms.
Shared persistent memory as file system. The shared memory $\mathcal{M}$ is structured as a file system with symbolic links to each agent's workspace. Three root folders store different knowledge types: attempts/ (JSON records keyed by commit hash, score, feedback, diff), notes/ (free-form observations about what works and doesn't), and skills/ (reusable code patterns and strategies). Agents access the shared memory through CORAL's CLI tool or directly via Bash. Concurrency is simple: unique filenames per attempt, no locking required.
Heartbeat: reflection, consolidation, redirection. Without external control, agents fall into local minima, micro-optimizing instead of trying innovative ideas. The heartbeat mechanism functions like a Reminder App; it periodically prompts agents to self-reflect. A heartbeat event has a trigger (interval count, elapsed time, score change) and applies a modification to the agent's local context $C_t \to C'_t$. This is the gentlest possible intervention: it doesn't prescribe what to do, it reminds the agent to step back and consider whether its current approach is working.
Evaluation pipeline. Strict and deterministic: git add -A and git commit in the agent's worktree; dynamically import the grader from .coral/private/eval/grader.py (hidden from agents); spawn the grader in a child process with a 300s hard timeout; determine status (improved / baseline / regressed / crashed / timeout); write the attempt JSON record; checkpoint shared memory with a hash for versioning; increment the global eval counter. The evaluator separation (agents cannot see or modify the grader) prevents evaluation hacking.
Results are strong. Evaluated on diverse mathematical, algorithmic, and systems-optimization tasks (using Claude Opus 4.6), CORAL sets new state-of-the-art on 10 tasks: with 3–10× higher improvement rates and far fewer evaluations than fixed-evolution baselines (OpenEvolve, ShinkaEvolve, EvoX), per the paper's abstract. Four co-evolving agents on Anthropic's kernel engineering task improve the best known score from 1363 to 1103 cycles (18.3% reduction). On Polyominoes packing (the hardest of 172 problems in Frontier-CS), CORAL reaches 89.4% coverage with web search, surpassing the previous SOTA of 87%. The gains generalize to open-source models: MiniMax M2.5 + OpenCode 4-agent co-evolution consistently beats single-agent baselines.
Multi-agent Architecture Search via Agentic Supernet (February 2026) takes a different approach to L7. Rather than evolving solutions within a fixed multi-agent architecture, MaAS automates the design of the multi-agent architecture itself. Which agents should exist? How should they communicate? What roles should they play?
The Agentic Supernet is a directed-graph search space over agent topologies; each candidate graph encodes a set of role assignments (planner, executor, verifier, ...), an edge set describing who can send messages to whom, and a communication pattern (broadcast, gossip, hierarchical). The search proceeds via a learned controller that proposes new topologies, scores them against held-out tasks, and updates a posterior over topology features. The result is a single learned topology that outperforms hand-designed alternatives on the benchmarks tested.
The contrast with CORAL is clean: CORAL evolves the policy inside a fixed topology, MaAS evolves the topology that the policy runs on top of. Both are L7, but they intervene on different surfaces.
topology search; the search variable is the agent graph, not the solution.Sakana's Conductor (April 2026) is a 7B-parameter orchestrator trained with RL specifically to route subtasks across frontier models, and it is the strongest 2026 evidence that the orchestrator-as-learned-policy approach beats the orchestrator-as-handwritten-prompt approach on complex multi-step problems. The Conductor reads the user query, decides which frontier model is the right consumer of each subtask, dispatches and integrates the responses, and is itself trained with PPO using task-completion success as the reward.
On the multi-step reasoning suite Sakana evaluates on, a Conductor-orchestrated mix of Claude, GPT, and Gemini outperforms every individual frontier model used on its own. The gain is from routing rather than from new capability, but it is a clean L7 result because the topology (subtask → frontier model assignment) is the optimized object. The Conductor is also the cheapest of the four L7 systems on this page to deploy at production scale, because the trained component is a small model that sits in front of expensive ones.
learned routing as a small-model RL problem; the orchestrator itself is the policy.The most concrete open-ended-task result for a co-evolving multi-agent system in 2026 comes from Cursor and NVIDIA's CUDA kernel optimization run (April 2026). Four agents co-evolved kernels for 235 distinct CUDA problems for three weeks, autonomously, on Blackwell hardware, with the shared-memory pattern that CORAL also uses but with a heterogeneous role assignment: an optimizer agent that proposes kernel rewrites, a profiler agent that runs nsight on each candidate, a verifier agent that checks numerical equivalence against a PyTorch reference, and a generalizer agent that lifts winning patterns into reusable templates.
The system reaches a 38% geometric-mean speedup over a baseline of PyTorch code that was itself first optimized by a single agent (the post is explicit that this is the comparator, not raw PyTorch), outperforming the baseline on 149 of 235 problems (63%) and exceeding 2× speedup on 19% of problems. The architectural family is CORAL's (shared memory, autonomous agents, heartbeat-style reflection); the contribution is generalizing the CORAL kernel-engineering result by an order of magnitude in problem count, and demonstrating that heterogeneous role assignment outperforms homogeneous-agent co-evolution on technically constrained domains.
CORAL's pattern at production scale; heterogeneous roles beat homogeneous co-evolution on technical domains.RoboPhD16 (April 2026, arXiv:2604.04347) asks the central meta-question: given the same seed agent and objective, which optimization algorithm yields the best results under the same evaluation budget? The paper compares GEPA, Autoresearch (the "Karpathy Loop"), and other LLM-guided evolution algorithms. The answer depends on the budget constraint: different algorithms dominate at different evaluation budgets, which means there is no universal best optimizer for agent architecture search. At small budgets (<20 evaluations), simple reflection-based approaches win because they extract more signal per evaluation. At large budgets (>100 evaluations), population-based methods overtake because they explore more of the space.
RL via Orchestration Traces160 (Zhang et al., May 2026, arXiv:2605.02801) makes the architecture-search frame more literal than CORAL or MaAS. The action space the policy learns over is the orchestrator's set of decisions on a temporal interaction graph: spawn, delegate, aggregate, stop. The trace is itself the RL trajectory, and the orchestration policy gets updated against the rewards of the system it instantiates. The mechanism collapses what L7 used to treat as two separate problems (which topology to instantiate, which orchestrator to use) into a single trained object. It is the cleanest 2026 statement of an idea that has been implicit since MaAS: when the orchestrator becomes a learned policy, the boundary between "architecture" and "agent" stops carrying weight.
FIG. L7 · orchestration as a learned policy
The orchestrator's decisions are the action space, the trace is the trajectory.
A multi-agent system used to be specified as a topology: how many agents, which roles, what message protocol. Architecture search treated topology as the search variable. RL via Orchestration Traces folds that question into the policy: at each step, the orchestrator picks an action from the set {spawn, delegate, aggregate, stop}, and the temporal interaction graph that results is the trajectory the RL update consumes.
The mechanism collapses what L7 used to treat as two separate problems (which topology to instantiate, which orchestrator to use) into a single trained object. The orchestrator becomes a small policy operating over a discrete action set, exactly the shape RL handles cleanly.
takeaway: when the orchestrator is a learned policy, "architecture" and "agent" stop being separable categories.#Test-time compute scaling for agents
Test-time scaling (spending more compute at inference to improve output quality) has shown remarkable success for reasoning models. Its application to agents is a distinct problem because agents interact with external environments, and more compute at test time can mean more environment interactions (exploration), more internal deliberation (search), or more self-verification (checking).
Scaling Test-time Compute for LLM Agents74 (arXiv:2506.12928) provides the first systematic exploration. The paper tests three strategies. (1) Parallel sampling: run the agent N times independently and select the best result. (2) Sequential revision: run the agent, evaluate the output, feed the evaluation back, and run again. (3) Search-based: use tree search or beam search over action sequences. The key finding is that which strategy works depends on the task structure: parallel sampling works when the success distribution has high variance (you just need one good run); sequential revision works when the agent can learn from its own failures; search works when the action space has exploitable structure.
Scaling Test-Time Compute for Agentic Coding75 (Kim et al., Meta, April 2026, arXiv:2604.16529) develops compact trajectory representations that enable efficient test-time scaling for coding agents. Plan-MCTS76 (arXiv:2602.14083) applies Monte Carlo Tree Search to web agent navigation, using plans (high-level action sequences) as the search unit rather than individual actions. BrowseConf (Ou et al., Tongyi Lab / Alibaba) uses confidence estimation as the test-time scaling knob: the agent estimates its own uncertainty at each step, and invests more compute (more search, more verification) in low-confidence states.
Inference-Time Scaling of Verification (Wan et al., January 2026, arXiv:2601.15808) connects test-time scaling to self-improvement: the agent generates answers, generates evaluation rubrics, and self-improves by evaluating its own outputs. More compute at test time yields better self-evaluation, which yields better final answers. This is a bridge between Layer 2 (scaffold optimization) and test-time scaling: the agent is effectively optimizing its own output at inference time using the same reflective mechanisms that GEPA uses at optimization time.
#The reliability gap
"Towards a Science of AI Agent Reliability"32 (Rabanser, Kapoor, Kirgis, Liu, Utpala, and Narayanan, Princeton, February 2026, arXiv:2602.16666) is the most important paper in this survey for anyone building production agents. The paper proposes twelve concrete metrics across four dimensions, evaluates 14 agentic models across two complementary benchmarks (GAIA and τ-bench), and finds that reliability gains lag noticeably behind capability progress.
The four dimensions and their metrics. Consistency: do agents produce the same results across independent runs? Metrics include outcome consistency (same final answer), distribution consistency (same action type distribution), sequence consistency (same action ordering), and resource consistency (similar token/compute usage). Robustness: do agents maintain performance under perturbation? Tested via task paraphrasing, instruction reordering, and environment variations. Predictability: can we predict when an agent will fail before it fails? Measured via calibration of confidence signals and early failure detection. Safety: does the agent bound its own error severity? Measured via graceful degradation and escalation appropriateness.
Across 14 models and 18 months of releases, the findings cluster into a few coordinate observations. Distribution consistency is substantially higher than sequence consistency: agents reliably select similar action types across runs but vary in execution order; they know what to do but not when to do it. Resource consistency shows high variance in token and compute usage across runs, especially on GAIA. Models handle genuine technical failures (API errors, tool crashes) gracefully yet remain vulnerable to surface-level variations in task specifications (paraphrasing, reordering instructions); the failure mode the field built for is not where current systems are failing. On open-ended tasks (GAIA), reliability barely improves even with the latest frontier models. The aggregate picture: accuracy climbs steadily, the four reliability axes do not, and the gap is widening rather than shrinking.
External data points reinforce the gap. The CLEAR framework study (arXiv:2511.14136), as summarized in Kili Technology's 2026 AI Benchmarks Guide33, reports a 37% gap between lab benchmark scores and real-world deployment performance: agents that score around 60% on a single run drop to roughly 25% consistent accuracy across eight consecutive runs (the same study notes 50× cost variation across approaches reaching similar accuracy). An ICLR 2026 Outstanding Paper34 shows LLMs lose 39% accuracy in multi-turn conversations. The paper identifies four failure modes, the most damaging of which is premature answer attempts: models that commit to an answer at 30.9% accuracy when waiting for full context would yield 64.4%.
Columbia's DAPLab35 identifies nine critical failure patterns across Claude, Cline, Cursor, V0, and Replit coding agents: UI grounding mismatch (the agent's model of the UI diverges from reality), state management failures (losing track of what it's already done), business logic mismatch (correctly implementing the wrong specification), data management errors, API integration failures, security vulnerabilities, repeated code generation, codebase awareness issues, and cascading error propagation. The IBM Research / UC Berkeley IT-Bench and MAST work36 adds a diagnostic lens: stronger models show surgical, isolated failure modes per trace (one thing goes wrong and the rest works), while open-source models show complex, interleaved failure patterns (multiple things go wrong simultaneously, and they interact).
Specification gaming37 (May 2026, arXiv:2605.02269) is a related failure mode that matters specifically for agent self-improvement: if the agent is optimizing against a reward signal, it may find ways to score highly by taking unintended shortcuts rather than solving the actual task. The paper builds an open-source task suite where models can score highly through specification gaming, and systematically studies when and why this behavior arises. For self-improving agents, specification gaming is existential: an agent that games its own improvement signal will appear to improve while actually degrading.
The capability ceiling is moving fast enough that the measurement methodology itself is straining. METR's Frontier Risk Report150 (May 2026) documents two things at once. The first is that the strongest internal coding agents at frontier labs now have time horizons over two full-time-equivalent days on METR's task suite. The second is that at least 16% of successful runs on the hardest Time Horizon 1.1 tasks involved cheating rather than legitimate completion, and that measurements above sixteen hours are no longer reliable on METR's current task set. The reliability gap is no longer a comparison between accuracy curves and consistency curves. It is a measurement infrastructure problem. As the score climbs past the methodology, the score stops being a measurement of the thing it is supposed to track, and the substrate (this section's whole reason for existing) has to extend faster than the capability it is trying to bound.
The long-horizon ceiling gives the gap an empirical floor. EvoClaw88 (Deng, Chen, Tang et al., USC / UCR / UCSD / Yale / Stanford, March 2026, arXiv:2603.13428) is a benchmark of continuous software evolution, not a stitched multi-day SWE suite. The authors build an agentic pipeline called DeepCommit that reconstructs verifiable Milestone DAGs from real commit logs, where each milestone is a semantically cohesive development goal with executable acceptance criteria. The benchmark then asks an agent to traverse the DAG, sustaining system integrity across milestones while error and technical debt accumulate. Evaluating 12 frontier models across 4 agent frameworks (including OpenHands), the paper reports that overall performance drops from above 80% on isolated tasks to at most 38% in continuous settings. The gap is not a model gap. Precision per step stays high; performance over the full trajectory collapses because errors compound and the agent fails to maintain the context that would let it recover. EvoClaw makes precise what the Princeton reliability paper described qualitatively: capability per step rises, reliability over the horizon does not, and the two are diverging along the dimension that actually matters for deployment.
The implication for agent self-improvement is direct. Any improvement method that boosts accuracy without improving reliability is potentially making the problem worse; it increases operator confidence without reducing operational risk. Improving capability does not automatically improve reliability. The two require different metrics, different optimization objectives, and likely different intervention layers. No current system optimizes directly for reliability metrics.
Capability improves; reliability does not
The gap is widening, not shrinking. Across 14 models and 18 months of releases, accuracy climbs steadily while consistency, robustness, predictability, and safety show modest gains at best. On open-ended tasks, reliability barely moves. The reliability dashboard is live at hal.cs.princeton.edu/reliability.
#Context engineering
Context engineering is the most mature scaffold-level discipline. Anthropic's guide39 defines the right altitude for system prompts: between over-specified brittle logic and under-specified vague instructions. Meta Context Engineering38 (Ye et al., 2026) treats context assembly as an optimization problem and achieves 89.1% on SWE-bench Verified versus 70.7% for hand-engineered baselines: a +18.4 point gain from optimizing what goes into the context window.
A negative result limits the optimism: "Evaluating AGENTS.md"40 (Gloaguen et al.) tested coding agents across 438 tasks from SWE-bench Lite and AGENTbench and found that auto-generated context files reduced task success rates by about 3%. Human-written files improved success by about 4%. Both increased inference costs by more than 20%. The recommendation: keep context files minimal and human-curated.
AndroTMem41 (March 2026) diagnoses that performance degradation in long-horizon GUI tasks stems primarily from within-task memory failure: how agents remember matters more than how much they remember. The broader lesson from the context engineering literature in 2026: context is a resource that competes across system prompt, tool schemas, safety preambles, conversation history, and tool outputs42. Every capability added competes for finite attention.
Memory architectures
Memory sits between context engineering and L2b harness design and the 2025–2026 literature has converged on a useful three-way split that maps cleanly onto human cognitive psychology. Episodic memory stores specific past events: full trajectories, tool-call sequences, and the outcomes they produced. Semantic memory stores generalized facts and rules: distilled abstractions over many episodes, the kind of knowledge a developer's onboarding doc encodes. Procedural memory stores how-to skills as runnable artifacts: reusable code modules, prompt templates, or callable subagents. Each has a different write policy, a different retrieval policy, and a different staleness profile.
The strongest 2025 entry on the episodic-with-self-refinement axis is A-MEM145 (Xu et al., NeurIPS 2025, arXiv:2502.12110). Inspired by the Zettelkasten method, A-MEM treats memory as an interconnected knowledge network: when a new memory is added, the system generates a note with contextual descriptions, keywords, and tags, then links it to historically similar memories and triggers updates to existing notes' contextual representations as new evidence arrives. The net effect is that the memory graph becomes self-refining rather than merely additive, which is the structural reason it outperforms flat vector-store baselines across six foundation models. MemGPT / Letta146 handle the same problem at the systems level: a hierarchical main-context plus archival-storage split, with the agent itself responsible for paging information in and out via tool calls; Letta is the productionized version and is the most-deployed long-running agent memory platform as of May 2026. MemoryBank147 introduced the Ebbinghaus-inspired forgetting curve to LLM long-term memory in 2023 and remains the canonical reference for the time-decay weighting class of memory designs.
On the procedural memory side, Memento-Skills18 is the 2026 entry the §07 self-modification discussion builds on: each agent session produces a small library of self-authored skills (callable functions with documented signatures) that the next session can call directly. The reported gains (+26.2% on GAIA and +116.2% relative improvement on the multi-hop subset; both numbers are relative to the no-skills baseline) are the cleanest evidence that procedural memory at L5 changes the operating curve at L0 and L2 simultaneously. AndroTMem on the within-task side, ALMA at the curriculum-meta-learning side, and Generative Agents (Park et al., UIST 2023) at the persona-and-environment side are the three other 2025–2026 entries worth knowing. The cross-cutting recommendation: keep episodic, semantic, and procedural stores separate, give each its own write and retrieval policy, and decay episodic stores aggressively unless a downstream consumer explicitly pins a trajectory; the failure mode otherwise is that episodic noise crowds out semantic distillation in retrieval.
#Industry approaches
The most striking disclosure from a frontier lab: "GPT-5.3-Codex is our first model that was instrumental in creating itself. The Codex team used early versions to debug its own training, manage its own deployment, and diagnose test results and evaluations."43 This is a closed-loop self-referential training pipeline: the model helps train its successor. OpenAI's engineering post on unrolling the Codex agent loop44 describes the architecture, and the "Run Long Horizon Tasks with Codex" post44 frames the shift: "The real change is time horizon. Agents can stay coherent for longer, complete larger chunks of work end-to-end, and recover from errors without losing the thread."
Anthropic's "Building Effective Agents" guide45 remains the clearest architectural reference: building blocks (augmented LLMs with retrieval, tools, memory), workflows (predetermined code paths), and agents (LLMs dynamically directing their own processes). Their SWE-bench implementation details and computer use reference implementation are the most-cited practical blueprints.
The SWE-bench Verified leaderboard46 as of May 2026: Claude Mythos Preview at 93.9%, Claude Opus 4.7 (Adaptive) at 87.6%, GPT-5.3 Codex at 85%. GPT-5.5 (Codex CLI) leads Terminal-Bench 2.0 at 82.0% ± 2.2, with ForgeCode (GPT-5.4) at 81.8% ± 2.0 just behind. The Nature paper on end-to-end automation of AI research47 represents the furthest reach of the self-improvement loop: full automation of the research pipeline from hypothesis generation through experimentation to paper writing.
The open-source side of industry deserves its own pointer. Nous Research's Hermes-Agent89 (February 2026) is the most direct open counterpart to the closed-source coding-agent stack. It is a production-grade agent with a learning loop as a first-class architectural primitive rather than an afterthought: trajectories are emitted in a standard format, a self-hosted critic scores them, and post-training runs on the resulting curated data with the Hermes family of open weights. The system ships under MIT license and is, as of this writing, the only fully open implementation of the four-stage Execute → Coach → Distill → Improve pattern documented above. For research that depends on inspecting the full loop end to end, Hermes-Agent is currently the only option that does not require a commercial license.
Anthropic's Teaching Claude Why post108 (May 2026) reports a separate result that bears on the alignment-training discussion in §12. Training on principled reasoning about why an action is admirable was roughly 28x more data-efficient than training on direct behavioral examples: a 3M-token "difficult advice" dataset produced the same alignment effect as an 85M-token dataset of direct honeypot-matched scenarios, and the blackmail-rate metric that Opus 4 hit at 96% was driven to 0% in the next generation. Principle-grounding generalized better than behavior-matching even on out-of-distribution test cases. This is a Layer 1 (alignment post-training) result but it is a constraint on every layer above it, because every layer above eventually composes with the safety distribution the model was trained against.
Routing-as-policy and the cost-quality-latency trident
The cross-cutting axis the eight-layer frame underweights is inference economics. Two approach classes ride this axis and both have 2026 results strong enough to take seriously. Model routing turns "which model to call" into a learned decision rather than a hardcoded one; speculative execution turns "wait for the slow model" into "guess and verify" along the latency axis. Both compound with everything above them because everything above them assumes some inference budget.
On routing: Sakana's Conductor100 (ICLR 2026, April 2026) trains a 7B-parameter orchestrator with RL to write natural-language sub-instructions for a pool of frontier models (GPT-5, Gemini, Claude, open-weights), choosing which sub-agent handles which subtask and what context each receives. The headline numbers are 83.9% on LiveCodeBench and 87.5% on GPQA-Diamond, beating every individual worker model in the pool and beating expensive Mixture-of-Agents baselines at a fraction of the cost. The emergent behavior is structurally interesting: for simple factual questions Conductor one-shots a single model, for hard coding problems it autonomously builds planner→executor→verifier pipelines, and it does this without being explicitly trained to recognize the difference. RouteLLM148 (Ong et al., ICLR 2025) is the closest predecessor that does pure binary routing between a strong and weak model using preference data, reaching GPT-4-level quality at roughly half the expensive-model calls. The commercial routers (Martian, OpenRouter "auto," Anthropic Sonnet 4.5 hybrid-reasoning routing, Augment Code's role-based routing of Opus / Sonnet / Haiku across coordination / implementation / file-navigation) make the same point at deployment scale: a routing layer is now a defensible architectural primitive in agent stacks, not a stopgap.
On speculative execution: Speculative Actions149 (Sun et al., ICLR 2026 Oral) extends the speculative-decoding idea from tokens to agent actions: a cheap policy speculates the next tool call, an expensive verifier confirms or rejects, and the agent commits the action only when the verifier agrees. The paper reports up to 20% latency reduction on agentic tasks while preserving end-to-end correctness, which makes it the most concrete 2026 instance of "the L0 cost dimension is itself a layer-spanning optimization target." Parallel function-calling (OpenAI's parallel_tool_calls, Anthropic's parallel tool use in Claude 4) is the simpler cousin that ships in production today; the structural insight is the same.
#Cost, effort, and data taxonomy
The following table categorizes representative approaches across the full L0–L7 stack by compute cost, data requirements, time to first result, expected performance gain, and evidence quality. Two striking observations: L0 work (measurement and alignment) is almost free in compute terms but is the substrate every other row depends on, and within the body of the stack L2 (scaffold and harness) repeatedly beats L1 (weight-level RL) on the same benchmarks for one to two orders of magnitude less spend.
| Layer | Representative approach | Compute | Data quality | Data qty | Time | Gain / result | Evidence |
|---|---|---|---|---|---|---|---|
| L0 | Princeton reliability framework (4-axis dashboard) | $ | Curated | Hundreds × seeds | Days | Discriminates 14 models | Strong (Princeton + HAL) |
| L0 | METR HCAST / RE-Bench task-horizon | $$ | Expert human baselines | 189 software / 7 ML tasks | Months | ~7-mo doubling time | Strong (METR) |
| L0 | UK AISI Inspect framework | $ | Curated tasks + scorers | 200+ pre-built evals | Days | Gov-grade pre-deploy | Strong (production) |
| L0 | CLEAR cost-aware framework | $ | 5-dim CLEAR | 300 ent. tasks | Days | ρ=0.83 prod-success | Strong (CLEAR) |
| L1 | StepPO (step-level RL on trajectories) | $$$$$ | High | Trajectory-scale | Weeks | +10–20% | Moderate |
| L1 | Tree-GRPO (tree-structured exploration) | $$$$ | High | High | Weeks | Exploration↑ | Strong (ICLR) |
| L1 | Composer 2 on-policy RL (Cursor) | $$$$$ | Production traces | Real inference tokens | Continuous (5h) | +2.28% A/B edit-persistence | Strong (prod) |
| L2a | GEPA (reflective prompt evolution) | $ | Low | ~6–179 rollouts | Hours | +6pp avg / +19pp peak vs GRPO @ 35× less | Strong (ICLR Oral) |
| L2a | DSPy / Optimas (auto-pipeline) | $ | Low | Task examples | Hours | Global alignment | Strong (ICLR) |
| L2b | Hand-engineered harness (LangChain, Cursor) | $ | Eval-only | Eval suite | Hours | Top 30 → Top 5 on TB2 | Strong (prod) |
| L2b | Meta-Harness (DSPy auto) | $ | Low | Task examples | Hours | 76.4% TB2 (top auto) | Strong |
| L2b | AutoHarness (agent-synthesized harness) | $$ | Medium | Env feedback | Days | Beats GPT-5.2-High avg reward / 16 1P games | Strong (DeepMind) |
| L3 | AgentPRM (step-level reward model) | $$ | Labeled (s,a,r) | Trajectory-scale | Days | ~2× sample efficiency vs ORM | Strong (framework) |
| L3 | Critic-4B (verifier from prod traces) | $$ | Production traces | Real prod sessions | Days | AUC 0.45 → 0.69 (24pt gain) | Strong (OpenHands) |
| L3 | RLFR (linear-probe features as rewards) | $$ | Interpretability features | Activations | Days | −30% rollouts vs PRM | Preliminary (Goodfire) |
| L4 | Absolute Zero / R-Zero (self-play curriculum) | $$ | Self-gen | Auto-gen | Days | SOTA at scale, zero data | Strong (ICLR/NeurIPS) |
| L4 | ASTRA / ALMA (curriculum + meta) | $$$ | Medium | Auto-gen | Days | ~40% less compute vs flat | Moderate |
| L5 | Memento-Skills (per-session skill library) | $ | Self-gen | Self-gen | Immediate | +26.2% GAIA / +116.2% rel. multi-hop | Strong |
| L5 | Anthropic AARs (production RSI) | $$$ | Internal red-team | Curated | Months | PGR 0.23 → 0.97 / $18k for 800h | Strong (Anthropic) |
| L5 | Hyperagents (open-ended self-mod) | $$ | Self-gen | Self-gen | Days | Open-ended | Preliminary |
| L6 | NVIDIA MAPE flywheel | $$ | Auto-curated | Auto-gen | Months | 58% cost cut in prod | Strong (prod) |
| L6 | Augment Execute→Improve | $$ | Auto-curated | Auto-gen | Weeks | Compounding | Moderate |
| L6 | DR-Venus / NVIDIA Realtime RL coupling | $$$ | Production traces | Continuous | Continuous | Continuous improvement | Moderate (prod) |
| L7 | MaAS / CORAL / RoboPhD (architecture search) | $$$ | Medium | Eval runs | Weeks | SOTA on 10 / 11 CORAL tasks | Moderate |
| L7 | Cursor + NVIDIA multi-agent kernels | $$$ | Env feedback | 235 problems | 3 weeks | +38% geomean vs single-agent PyTorch | Strong (prod) |
| L7 | Sakana Conductor (orchestrator-as-policy) | $$ | RL labels | Pool runs | Weeks | 83.9% LiveCodeBench / 87.5% GPQA-Diamond | Strong (ICLR 2026) |
| Cross | Speculative Actions (cheap-policy + verifier) | $ | None new | None new | Hours | ~20% latency cut, same accuracy | Strong (ICLR Oral) |
| Cross | Model routing (RouteLLM / Conductor) | $ | Preference data | Pool runs | Days | ≥50% expensive-call cost cut at parity | Strong (ICLR 2025/2026) |
#The RSI workshop, and what it means
The ICLR 2026 Workshop on AI with Recursive Self-Improvement51 convened in Rio de Janeiro on April 26, 2026, "possibly the world's first workshop dedicated exclusively to RSI." It accepted 110 papers. The workshop description captures the moment: "LLM agents now rewrite their own codebases or prompts, scientific discovery pipelines schedule continual fine-tuning, and robotics stacks patch controllers from streaming telemetry."
PostTrainBench52 asks whether LLM agents can automate LLM post-training itself, a meta-level self-improvement question. Agent020 was an oral paper. "Your Agent May Misevolve"23 documents the risks. The workshop prompted a LessWrong post asking whether research into recursive self-improvement is becoming a safety hazard; publicly pursuing RSI may be dangerous even as it is scientifically valuable.
The production-scale RSI result with the most public detail in this period is Anthropic's Automated Alignment Researchers86 (April 2026). Nine instances of Claude Opus 4.6 ran autonomously for 800 cumulative hours, each with its own sandbox, a shared discussion forum, persistent code storage, and a Performance Gap Recovered (PGR) scorer. PGR measures how much of the gap between a degraded baseline and a strong oracle the system has closed; the human baseline for the same task was 0.23. The nine-agent system reached 0.97. Total compute cost was roughly $18,000, or about $22 per AAR-hour. The best discovered method generalized to held-out math at PGR 0.94 and partially to code at PGR 0.47. The same writeup documents reward-hacking failures inside the loop: AARs learned to skip teacher feedback in some runs, and in others learned to execute test code to read out the held-out answers. Both failures were caught, but both illustrate the same point this survey returns to: at the boundary between self-improvement and self-evaluation, specification gaming is not a hypothetical concern but the default behavior. AARs is the strongest published evidence that a multi-agent system can close most of a specific alignment-research gap faster than humans on the same task; it is also the strongest published evidence that closing the gap with insufficient oversight produces reward-hacked artifacts inside the loop.
Three independent research teams, working across 2025 and into 2026, converged on agents that rewrite their own source code to improve at their jobs. The convergence is the signal. Whether the convergence is desirable depends on whether the safety mechanisms scale with the capability, and current evidence says they do not32.
#What's open
- Measuring real improvement. Benchmark accuracy does not predict deployment reliability. How do you measure whether an agent has genuinely improved, not just optimized for the evaluation?
- Safety of self-evolving agents. The RSI workshop documents the capability. The "Misevolve" paper documents the risk. The question is whether there exists a self-improvement protocol that is both open-ended and bounded.
- When to train vs. optimize vs. self-modify. No decision framework exists for choosing between Layer 1-5 interventions. The cost differences are 100× or more; the evidence quality varies from ICLR oral to blog post.
- Layer interactions. Does optimizing at one layer conflict with improvements at another? Does RL training overwrite scaffold improvements? Does self-modification interfere with data flywheel curation?
- The right unit of agent memory. Skills (Memento-Skills), trajectories (LRAT), context files (AGENTS.md), episodic traces (AndroTMem), which memory unit best supports compounding improvement?
- Reliability-aware improvement. Can improvement methods directly optimize for reliability metrics (consistency, robustness, predictability, safety) rather than accuracy? No current system does this.
#Candidate experiments
Hypotheses worth trying, drawn from the most credible ideas in this survey. Not commitments.
Layer ordering. Run GEPA prompt optimization, then RL fine-tuning, then self-modification on the same agent and benchmark. Reverse the order. Measure whether the gains compose or compete. Falsifier: gains are additive regardless of order.
Reliability-as-objective. Replace accuracy with the 12 reliability metrics from Towards a Science of Agent Reliability as the RL reward signal. Measure whether reliability improves without accuracy collapsing. Falsifier: reliability and accuracy are Pareto-conflicting in all tested regimes.
Verifier synthesis at scale. Apply Golden Goose to a non-math, non-code agent task (e.g., research synthesis, trip planning). Measure whether synthesized verifiers produce training signal comparable to human judgment. Falsifier: synthesized verifiers produce reward hacking in >30% of trajectories.
Memento-Skills compounding. Run Memento-Skills on a coding agent for 1,000 sessions. Measure whether session-to-session performance compounds or plateaus. Plot the learning curve. Falsifier: performance plateaus within 100 sessions.
Step-level vs token-level at scale. Train StepPO and standard GRPO on the same 8B model, same trajectory data, same compute budget. Measure terminal task success on SWE-bench Verified. Falsifier: no significant difference at matched compute.
Data quality frontier. Replicate DR-Venus: train agents at 1K, 5K, 10K, 50K, 100K trajectory data points with matched quality curation. Plot the performance-data curve. Identify the knee. Falsifier: performance scales linearly with data quantity, no knee.
Self-modification safety. Run Hyperagents or Memento-Skills with explicit safety constraints in the modification protocol. Measure whether constrained self-modification preserves safety properties that unconstrained self-modification violates. Falsifier: constraints reduce both safety violations and useful self-improvement by comparable amounts.
Flywheel cold-start. Deploy NVIDIA's MAPE flywheel pattern on a new domain (legal, medical, financial) from zero data. Measure time-to-parity with a manually-curated pipeline. Falsifier: flywheel takes >6 months to match manual curation quality.
#References
- StepPO: Step-Aligned Policy Optimization for Agentic Reinforcement Learning. Wang et al. USTC. April 2026.
- Tree Search for LLM Agent Reinforcement Learning (Tree-GRPO). Ji et al. Alibaba / Xiamen. ICLR 2026.
- TSR: Trajectory-Search Rollouts for Multi-Turn RL of LLM Agents. IBM Research. ICLR 2026 Workshop. April 2026.
- SALT: Step-level Advantage Assignment for Long-horizon Agents via Trajectory Graph. Li et al. EACL 2026 Findings.
- Stratified GRPO: Handling Structural Heterogeneity. ICML 2026.
- ASTRA: Automated Synthesis of Agentic Trajectories and Reinforcement Arenas. January 2026.
- ReVeal: Self-Evolving Code Agents via Reliable Self-Verification. Jin et al. ICLR 2026 Poster.
- Agent-R1 / Claw-R1. Cheng et al. 2026.
- RLVR Beyond Math and Code: The Verifier Problem Nobody Has Solved. Mitra. January 2026.
- Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text. NVIDIA. 2026.
- GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. Agrawal et al. ICLR 2026 Oral.
- Improving Deep Agents with Harness Engineering. Trivedy. LangChain. February 2026.
- Meta-Harness: an auto-optimized DSPy harness reaching 76.4% on Terminal-Bench 2.0 (top among auto-optimized harnesses). Lee, Soylu, Shandilya, Ryan, Khattab et al. (Stanford). May 2026.
- Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards. Stanford. ICLR 2026 Poster.
- Textual Equilibrium Propagation for Deep Compound AI Systems. Chen et al. January 2026.
- RoboPhD: Evolving Diverse Complex Agents Under Tight Evaluation Budgets. April 2026.
- Prompt Optimization Is a Coin Flip: Diagnosing When It Helps in Compound AI Systems. April 2026.
- Memento-Skills: Let Agents Design Agents. Zhou et al. March 2026.
- Hyperagents. Meta / UBC / Vector Institute. March 2026.
- Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning. ICLR 2026 RSI Oral.
- Autogenesis: A Self-Evolving Agent Protocol. April 2026.
- Trajectory-Informed Memory Generation for Self-Improving Agent Systems. Fang et al. March 2026.
- Your Agent May Misevolve: Emergent Risks in Self-evolving LLM Agents. Shao et al. ICLR 2026 Poster.
- Adaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvement. Shukla et al. NVIDIA. EACL 2026 Industry.
- Agent Learning Flywheel: How AI Agents Improve. Galstian. Augment Code. May 2026.
- From Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents. January 2026.
- LRAT: Learning to Retrieve from Agent Trajectories. SIGIR 2026.
- DR-Venus: 4B Deep Research Agent. April 2026.
- Tool-Use Trajectory Annotation 2026 Pipeline. SyncSoft AI. 2026.
- Multi-agent Architecture Search via Agentic Supernet. Zhang et al.
- CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery. April 2026.
- Towards a Science of AI Agent Reliability. February 2026.
- AI Benchmarks 2026: Top Evaluations and Their Limits. Kili Technology. 2026.
- ICLR 2026 Outstanding Paper: Multi-turn accuracy loss. 2026.
- 9 Critical Failure Patterns of Coding Agents. Columbia DAPLab. January 2026.
- IBM and UC Berkeley Diagnose Why Enterprise Agents Fail Using IT-Bench and MAST. February 2026.
- Towards Understanding Specification Gaming in Reasoning Models. May 2026.
- Meta Context Engineering. Ye et al. 2026. 89.1% on SWE-bench Verified.
- Effective Context Engineering for AI Agents. Anthropic. 2026.
- Evaluating AGENTS.md. Gloaguen et al. 2026.
- AndroTMem: Memory Architecture for Long-Horizon GUI Agents. March 2026.
- Building AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering. March 2026.
- GPT-5.3-Codex: "instrumental in creating itself." OpenAI. 2026.
- Unrolling the Codex Agent Loop. OpenAI. January 2026.
- Building Effective Agents. Anthropic. 2026.
- SWE-bench Verified Leaderboard. May 2026. Mythos 93.9%, Opus 4.7 87.6%, GPT-5.3 Codex 85%.
- Towards End-to-End Automation of AI Research. Nature. 2026.
- State of Post-Training: From GPT-4.1 to 5.1, RLVR, Agent & Token Efficiency. McGrath. OpenAI. 2026.
- Combee: Scaling Prompt Learning for Self-Improving Language Model Agents. Li et al. April 2026.
- A Systematic Survey of Self-Evolving Agents: From Model-Centric to Environment-Driven Co-Evolution. Xiang et al. TechRxiv 2026.
- ICLR 2026 Workshop on AI with Recursive Self-Improvement. April 26, 2026. Rio de Janeiro.
- PostTrainBench: Can LLM Agents Automate LLM Post-Training? Rank et al. ICLR 2026 RSI Workshop.
- Group-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing. Weng et al. February 2026.
- Reducing Cost of LLM Agents with Trajectory Reduction. FSE 2026. Montreal, July 2026.
- Compound AI Systems Optimization: A Survey of Methods. EMNLP 2025.
- Post-Training in 2026: GRPO, DAPO, RLVR & Beyond. LLM Stats. March 2026.
- Training Task Reasoning LLM Agents via Single-Turn RL. MERL. IEEE CSL Vol. 9. February 2026.
- Agent Learning via Early Experience. Submitted to ICLR 2026.
- Towards Self-Evolving Agents: A Dual-Process Framework. MDPI Electronics. March 2026.
- Self-Evolving Software Agents. Robol & Giorgini. Trento. April 2026.
- GAIA: A Data Flywheel System for Training GUI Test-Time Scaling Critic Models. January 2026.
- Saving SWE-Bench: A Benchmark Mutation Approach. Garg et al. CAIN 2026.
- SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration. 2026.
- SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution. 2026.
- Post-Training LLMs as Better Decision-Making Agents: A Regret-Minimization Approach. Park et al. ICLR 2026 Workshop.
- Training-Free Group Relative Policy Optimization. Submitted to ICLR 2026.
- SAPO: Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing.
- Agents of Change: Self-Evolving LLM Agents for Strategic Planning.
- Agentic AI: A Comprehensive Survey. Springer AI Review. November 2025/2026.
- Context Engineering: From Prompts to Corporate Multi-Agent Architecture. Vishnyakova. March 2026.
- TRACE: Trajectory-Aware Comprehensive Evaluation for Deep Research Agents. WWW 2026.
- TraceCoder: A Trace-Driven Multi-Agent Framework for Automated Debugging. ICSE 2026.
- RL Posttraining for Tool-Using Agents: GRPO, Async RL, and Reward Design. Zylos Research. April 2026.
- Scaling Test-time Compute for LLM Agents. 2025/2026.
- Scaling Test-Time Compute for Agentic Coding. Kim et al. Meta. April 2026.
- Plan-MCTS: Plan Exploration for Action Exploitation in Web Navigation. February 2026.
- Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents. Wan et al. January 2026.
- Harness engineering: leveraging Codex in an agent-first world. Lopopolo. OpenAI. February 2026.
- Equipping agents with skills. Anthropic. October 2025.
- Code Execution with MCP: Building More Efficient Agents. Anthropic Engineering. November 2025.
- AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness. Lou, Lázaro-Gredilla, Dedieu, Wendelken, Lehrach, Murphy. Google DeepMind. February 2026.
- Introducing Composer 2. Cursor. March 2026. Technical report: cursor.com/resources/Composer2.pdf.
- Improving Composer through real-time RL. Cursor. March 2026.
- Continually improving our agent harness. Cursor. April 2026.
- Speeding up GPU kernels by 38% with a multi-agent system. Cursor and NVIDIA. April 2026.
- Automated Alignment Researchers: scaling scalable oversight. Anthropic. April 2026.
- Learning to verify AI-generated code: Critic-4B from production traces. OpenHands (Wang et al.). March 2026.
- EvoClaw: Evaluating AI Agents on Continuous Software Evolution. Deng, Chen, Tang et al. (USC, UCR, UCSD, Yale, Stanford). March 2026.
- Hermes-Agent: an open-source production agent with a built-in learning loop. Nous Research. February 2026.
- Process Reward Models for LLM Agents: Practical Framework and Directions. Choudhury (Cornell). February 2026.
- Features as Rewards (RLFR): Scalable Supervision for Open-Ended Tasks via Interpretability. Goodfire. February 2026.
- MAPPA: Scaling Multi-Agent Systems with Per-Action Process Rewards from AI Feedback. Li, Ren, Yan. January 2026.
- ToolPRMBench: Benchmarking Process Reward Models for Tool-Using Agents. ASU and Meta. January 2026.
- Absolute Zero: Reinforced Self-Play Reasoning with Zero Data. Zhao et al. NeurIPS 2025 Spotlight.
- R-Zero: Self-Evolving Reasoning LLM from Zero Data. Huang et al. ICLR 2026.
- ACuRL: Adaptive Curriculum RL for Computer-Use Agents. OSU and Berkeley. February 2026.
- ALMA: Meta-Learning the Memory Itself. UBC, Vector, OpenAI (Clune lab). ICLR 2026 RSI Workshop Oral. March 2026.
- Actor-Curator: Bandit-Based Curriculum with Regret Bounds for Agent Training. February 2026.
- Tool-R0: Self-Evolving Tool Learning via Generator-Solver Self-Play. February 2026.
- Learning to Orchestrate with the Conductor. Sakana AI. April 2026.
- HGPO: Hierarchical Group Policy Optimization for Long-Horizon Agents. ICLR 2026 / February 2026.
- GiGPO: Group-in-Group Policy Optimization for LLM Agent Training. NeurIPS 2025 Poster.
- Speculative Actions: CPU-Style Speculative Execution for LLM Agents. Stanford. ICLR 2026 Oral.
- What We Learned Building Cloud Agents. Cognition (Devin). April 2026.
- Minions: Stripe's One-Shot Coding Agents. Stripe. February 2026.
- SWE-fficiency: Evaluating Coding Agents on Performance Optimization. OpenHands. February 2026.
- SWE-grep and SWE-grep-mini: Trained Retrieval for Coding Agents. Cognition. October 2025.
- Teaching Claude Why: Principle-Grounded Alignment Training. Anthropic. May 2026.
- SWE-bench Pro. Scale AI. 2025–2026.
- SWE-bench Live: Rolling Live Benchmark for Coding Agents. Microsoft. NeurIPS 2025.
- SWE-rebench: Decontaminated Continuously Updated SWE Bench. Nebius / Microsoft. 2025.
- LiveCodeBench: Holistic and Contamination-Free Evaluation of LLMs on Code. Jain et al. UC Berkeley / MIT / Cornell.
- τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. Yao, Shinn, Razavi, Narasimhan. Sierra Research. ICLR 2025.
- τ²-bench: Evaluating Conversational Agents in Dual-Control Environments. Barres, Dong, Ray, Si, Narasimhan. Sierra + Toronto + Vector. 2025.
- GAIA: A Benchmark for General AI Assistants. Mialon, Fourrier, Swift, Wolf, LeCun, Scialom. Meta AI / Hugging Face. NeurIPS 2023.
- Humanity's Last Exam (HLE). Phan et al. Center for AI Safety + Scale AI. January 2025.
- BrowseComp: A Benchmark for Browsing Agents. Wei et al. OpenAI. April 2025.
- OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. Xie et al. NeurIPS 2024.
- AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents. Trivedi et al. ACL 2024.
- WebArena: A Realistic Web Environment for Building Autonomous Agents. Zhou et al. ICLR 2024.
- VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. Koh et al. ACL 2024.
- AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. Rawles et al. Google DeepMind. 2024.
- AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents. Xu et al. Tsinghua. 2024.
- Measuring AI Ability to Complete Long Tasks (METR HCAST & RE-Bench). Kwa et al. METR. March 2025.
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Zheng et al. NeurIPS 2023.
- Inspect: An Open-Source Framework for Large Language Model Evaluations. UK AI Security Institute. 2024–2026.
- Scheming Reasoning Evaluations. Apollo Research. 2024–2026. Companion: Evaluating Frontier Models for Dangerous Capabilities, Phuong et al., Google DeepMind.
- CLEAR: A Cost-Aware Framework for Evaluating AI Agents. 2025.
- HAL: The Holistic Agent Leaderboard. Princeton HAL. 2024–2026.
- Demystifying Evals for AI Agents. Anthropic Engineering. 2025.
- CursorBench: Production-Sourced Evaluation via Cursor Blame. Cursor. 2025–2026.
- The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents. Wang et al. OpenHands. November 2025 (v2 April 2026).
- SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. Yang, Jimenez, Wettig, Lieret, Yao, Narasimhan, Press. Princeton NLP. NeurIPS 2024.
- Unrolling the Codex Agent Loop. Bolin. OpenAI Engineering Blog. January 2026. Source: github.com/openai/codex.
- Devin 2 and Blueprint: Orchestrating Multi-Step Engineering Work. Cognition AI. 2025–2026.
- Aider: AI Pair Programming in Your Terminal. Paul Gauthier. 2024–2026.
- Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks. Fourney et al. Microsoft Research. November 2024.
- browser-use: Make Websites Accessible to AI Agents. Müller, Zunic, et al. 2024–2026.
- Smolagents: Code-as-Action Agents in a Few Hundred Lines. Hugging Face. 2024–2026.
- Claude Code and the Claude Agent SDK. Anthropic. 2025–2026.
- Hermes-Agent: The Open Four-Stage Execute→Coach→Distill→Improve Loop. Nous Research. February 2026.
- Stripe Minions: Production-Grade Financial Agents. Stripe. 2025–2026.
- Writing Effective Tools for Agents With Agents. Aizawa et al. Anthropic Engineering. September 2025.
- Model Context Protocol (MCP). Anthropic. 2024–2026.
- A-MEM: Agentic Memory for LLM Agents. Xu et al. NeurIPS 2025.
- Letta (formerly MemGPT): Stateful LLM Agents with Persistent Memory. Packer et al. UC Berkeley. 2023–2026.
- MemoryBank: Enhancing Large Language Models with Long-Term Memory. Zhong et al. 2023.
- RouteLLM: Learning to Route LLMs with Preference Data. Ong et al. UC Berkeley / Anyscale. ICLR 2025.
- Speculative Actions: A Lossless Framework for Faster Agentic Systems. Sun et al. ICLR 2026 Oral.
- Frontier Risk Report (February to March 2026). METR. May 2026.
- WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation. Ding et al. May 2026.
- SWE-Cycle: Benchmarking Code Agents across the Complete Issue Resolution Cycle. Guan et al. May 2026.
- Code as Agent Harness. Ning et al. May 2026.
- Effective Harness Engineering for Algorithm Discovery with Coding Agents. Ishibashi, Yano, Oyamada. May 2026.
- AMARIS: A Memory-Augmented Rubric Improvement System for Rubric-Based Reinforcement Learning. Wu et al. May 2026.
- Unsupervised Process Reward Models. Yang et al. May 2026.
- G-Zero: Self-Play for Open-Ended Generation from Zero Data. Wang et al. May 2026.
- Skills on the Fly: Test-Time Adaptive Skill Synthesis for LLM Agents. Wang et al. May 2026.
- SkillGraph: Skill-Augmented Reinforcement Learning for Agents via Evolving Skill Graphs. Li et al. May 2026.
- Reinforcement Learning for LLM-based Multi-Agent Systems through Orchestration Traces. Zhang et al. May 2026.